Umelá inteligencia - data augmentation
Pre dobré výsledky pri vyhodnocovaní obrazu neurónovou sieťou potrebujeme približne tisíc obrázkov pre každú kategóriu ktorú chceme rozpoznávať. Toto množstvo je často nedosiahnuteľné a preto si môžeme vyrobiť ďalšie obrázky z tých čo už máme, tak že na ne aplikujeme rôzne grafické efekty po anglicky sa tomu hovorí data augmentation.
Úvod
V minulom zápisku som písal ako si zabezpečiť dataset.Moje osobné skúsenosti sú, že pokiaľ máme tisíc obrázkov, tak dostaneme výborné výsledky, určité riešenia budú dobre fungovať aj s päťsto obrázkami a čiastočne aj sto obrázkami.
Pri riešení určitých problémov máme obrázkov napríklad len desať, dvadsať, tridsať a tu nám pomôže Keras.
Keras Image Preprocessing
V Kerase máme na toto výborný nástroj Image Preprocessing. S ním si môžeme obrázok rotovať, posunúť, zmeniť jas, zošikmiť, zväčšiť, zmenšiť, prípadne preklopiť.Takže sa vrátime k nápadu, že chceme na obrázkoch identifikovať našu mamu a máme k tomu v našom prípade dvadsaťdva fotiek Angelina Jolie :-)
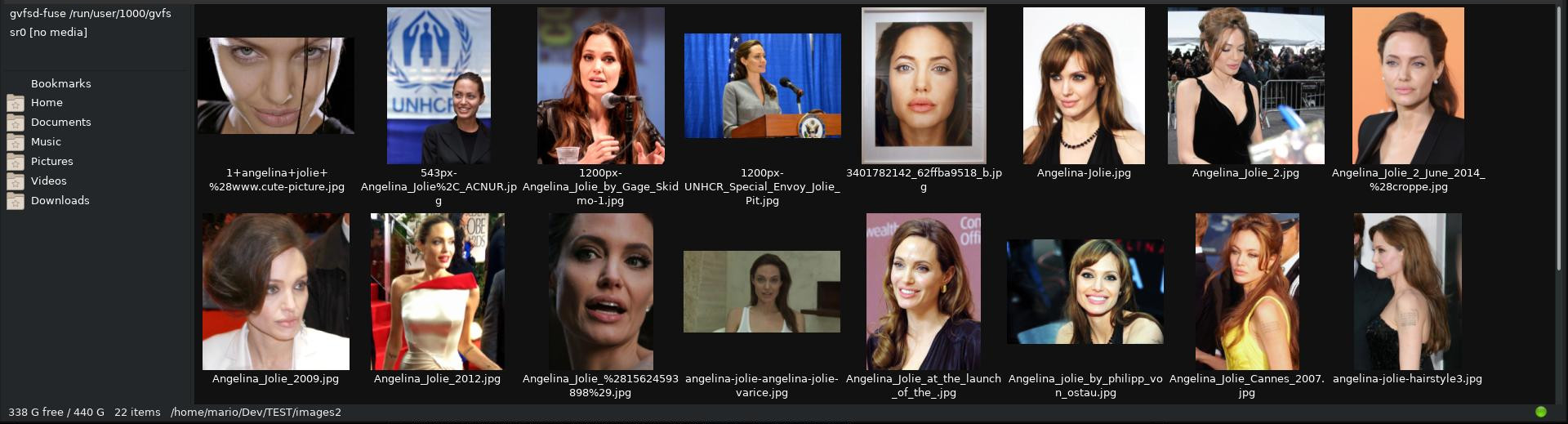
Klasicky z ImageDataGenerator lezú náhodne upravené obrázky podľa nami zvolených pravidiel. Keď chceme mať nad týmto procesom kontrolu aby sme výsledok upravených obrázkov videli môžeme použiť tento skript.
Nainštalujeme si ho:
git clone https://github.com/bedna-KU/Controlled-data-augmentation-with-Keras cd Controlled-data-augmentation-with-KerasAk chceme vidieť náhľad pred samotným vygenerovaním obrázkov, použijeme príkaz:
python3 keras_data_aug.py --count 25 --input "images" --output "images_aug" --action show
Zobrazí sa nám náhľad z náhodne vybraného obrázka.

Ak sa nám výsledok páči vygenerujeme si obrázky príkazom:
python3 keras_data_aug.py --count 25 --input "images" --output "images_aug" --action save--count 25 nám hovorí, že sa vyrobí 25 náhodných obrázkov.
--input je priečinok so vstupnými obrázkami.
--output je priečinok kde sa uložia vygenerované obrázky.
--action je akcia ktorá sa vykoná. Pre náhľad zadáme show a pre uloženie save.
Takto získame 22 x 25 = 550 vygenerovaných obrázkov, čo je aj s našimi pôvodnými dvadsaťdva obrázkami päťstosedemdesiatdva obrázkov, čo už je celkom dosť aby nám umelá inteligencia dokázala obrázky rozlišovať.
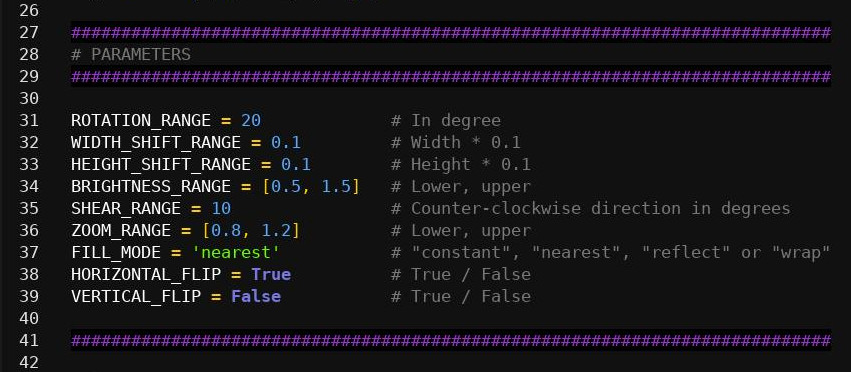
Parametre generovania si nastavíme priamo v kóde
Rozostrenie a šum
Dosť dobre pomáha, keď do obrázkov pridáme rozostrenie, alebo šum, tým zas pomôžeme našej neurónovej sieti aby sa nenaučila len na konkrétne obrázky z nášho datasetu. Keď sa chceme pozrieť ako by takto upravený obrázok vyzeral spustíme skript pre náhľad:python3 blur_and_noise.py --input images --output images_aug --action show

Ak chceme vygenerovať rozostrené obrázky použijeme:
python3 blur_and_noise.py --input images --output images_aug --action blurNo a ak chceme vygenerovať zašumené obrázky použijeme:
python3 blur_and_noise.py --input images --output images_aug --action noiseKeď sa rozhodneme, že k našim päťstosedemdesiatdva obrázkom vygenerujeme ešte päťstosedemdesiatdva rozostrených obrázkov budeme mať spolu tisíc stoštyridsaťštyri obrázkov a to už by nám na naučenie našej neurónovej siete malo stačiť.
Prílohy

Preview_window_keras_data_augmentation.png
(1.2 MB)

input_images.jpg
(204.5 kB)

keras_data_augmentation_parameters.jpg
(96.4 kB)

blur_and_noise.png
(2.7 MB)

Pre pridávanie komentárov sa musíte prihlásiť.