FreeRTOS tracing bez komerčného softvéru
Operačný systém FreeRTOS dokáže počas behu zaznamenávať rôzne systémové udalosti ako napr. presné časovanie prepínania úloh. Práve táto časť je pre kooperatívny multitasking kľúčová. V nasledujúcom blogu si ukážeme, ako jednoducho zaznamenávať a zobrazovať prácu správcu úloh pomocou OSS softvéru.
Aký softvér máme k dispozícii?
Na vizualizáciu práce FreeRTOS exituje skvelý komerčný nástroj Percepio Tracealyzer. Z ponuky OSS softvéru som nenašiel prakticky nič. Skúsil som teda napísať niečo vlastné.
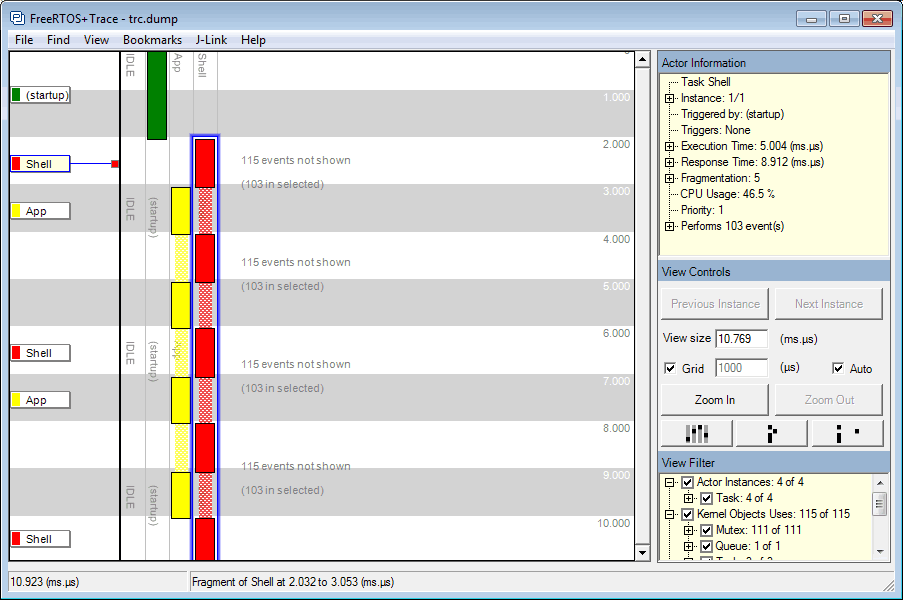
Záznam práce plánovača úloh na strane FreeRTOS
Pre pridanie zaznamenávania práce plánovača stačí zapnúť nastavenie configUSE_TRACE_FACILITY vo FreeRTOSConfig.h a definovať makrá traceTASK_CREATE a traceTASK_SWITCHED_IN.
#define configUSE_TRACE_FACILITY 1 #undef traceTASK_CREATE #define traceTASK_CREATE(pxNewTCB) \ trcKERNEL_HOOKS_TASK_CREATE(pxNewTCB->uxTCBNumber, pxNewTCB->pcTaskName); #undef traceTASK_SWITCHED_IN #define traceTASK_SWITCHED_IN() \ trcKERNEL_HOOKS_TASK_SWITCH(pxCurrentTCB->uxTCBNumber);
Ďalej je potrebné ešte definovať funkcie trcKERNEL_HOOKS_TASK_CREATE a trcKERNEL_HOOKS_TASK_SWITCH.
Konkrétna implementácia týchto funkcií bude závisieť od použitej platformy. Na Linuxe budú tieto funkcie zaznamenávať prácu plánovača do súboru. Na inom hardvéri to môže byť napríklad UART, alebo SD karta. Ako príklad tu však uvediem implementáciu práve pre desktop.
Celý kód je k dispozícii na mojom githube. Je to pomerne jednoduchý kód, ktorý vytvorí 2 súbory - hlavičku s názvami úloh a záznam bežiacich úloh.
Vizualizácia
Pre vizualizáciu som zvolil program PulseView. Skôr než zobrazíme súbor ho musíme konvertovať na niektorý z podporovaných formátov.
Ide zase o jednoduchý program, ktorý parsuje binárny trace. Celý zdrojový kód je opäť na mojom githube.
Zastavme sa ešte na chvíľu pri formáte. Navrhol som jednoduchý, ľahko parsovateľný, kompaktný binárny formát vhodný ako pre počítač tak aj pre jednoduchší hardvér.
Hlavička má formát za sebou uložených záznamov. Každý záznam vyzerá nasledovne:
I L NNNNNNNNN | | | | | `- Názov úlohy | `- Dĺžka názvu úlohy (1 byte) `- ID úlohy (1 byte)
Maximálna dĺžka názvu môže byť 255 znakov. Štruktúra zaberá málo priestoru v pamäti a dá sa veľmi ľahko pasovať.
Práca plánovača úloh je zase zaznamenaná vo forme po sebe idúcich záznamov. Každý záznam obsahuje na začiatku časový údaj od posledného záznamu nasledovaný dátami fixnej dĺžky. Časový údaj môže byť 62-bitový. Časové údaje majú premenlivú dĺžku od 8 bitov po 64 bitov. Prvé 2 bity určujú dĺžku čísla.
00XXXXXX - 6-bitové číslo 01XXXXXX XXXXXXXX - 14-bitové číslo 10XXXXXX XXXXXXXX XX... 30-bitové číslo 11XXXXXX XXXXXXXX XX... 62-bitové číslo
Keďže zaznamenávame čas od predchádzajúcej udalosti budú časové značky väčšinou 6, alebo 14 bitové, čo výrazne redukuje priestor potrebný pre uloženie záznamu.
Z binárneho formátu sa následne generuje Value Change Dump formát. Rozhodol som sa práve pre tento formát, pretože tuším ako jediný z projektu sigrok podporoval riedke dáta.
Konkrétnymi nechutnosťami formátu sa nebudem zaoberať. V zásade je to jednoduchý formát, ktorý používa ascii a zvyšok nájdete v špecifikácii.
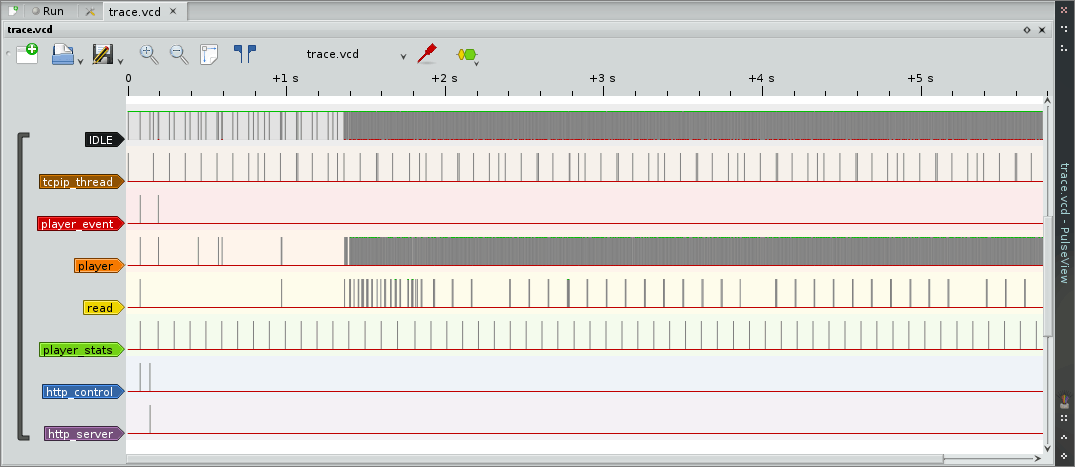
Výsledný záznam stačí načítať do PulseView. Na zázname je krásne vidieť, ktoré úlohy najviac blokujú vykonávanie programu. Na základe tohto záznamu je možné ľahko identifikovať miesta, v ktorých je napríklad vhodné pridať explicitné prepnutie úlohy (taskYIELD), alebo ktorým úlohám je potrebné zvýšiť prioritu.
Tuning PulseView
Okrem toho som sa zaoberal aj možnosťou zobraziť kombinovaný trace zo všetkých úloh v jednom riadku. Teoreticky to je možné dosiahnuť vlastným dekóderom pre sigrok, ale prakticky sa to nepoužíva až tak dobre, pretože nie je možné naskriptovať prepojenie vstupov s dekóderom. Vstupy sa preto musia vyklikať ručne. Ak by sa však niekomu chcelo babrať s interným formátom sigrok-u malo by byť možné vložiť nastavenia priamo do generovaného súboru.
Dekóder pre sigrok je jednoduchý python skrip, ktorý je umiestnený niekde v /usr/lib, alebo adresári definovaným premennou SIGROKDECODE_DIR. Pre umiestnenie v domovskom adresári definujeme:
export SIGROKDECODE_DIR=~/.sigrok/decoders
Vytvoríme adresár ~/.sigrok/decoders/freertos_task_tarce a vytvoríme v ňom súbory __init__.py a pd.py. V __init__.py bude jediný import:
from .pd import Decoder
V pd.py je samotný dekóder. Áno, je hnusný s hardcodovanými názvami a počtom kanálov. Nie je však problém načítať počet kanálov a názvy z externého zdroja (súboru hlavičky).
import sigrokdecode as srd import sys task_names = [ 'IDLE', 'tcpip_thread', 'player_event', 'player', 'read', 'player_stats', 'http_control', 'http_server', ] NUM_CHANNELS = 8 class Decoder(srd.Decoder): api_version = 3 id = 'freertos_task_tarce' name = 'FreeRTOS task' longname = 'FreeRTOS task trace' desc = 'Visualize FreeRTOS task trace' license = 'gplv2+' inputs = ['logic'] outputs = ['freertos_task_tarce_out'] tags = ['Util'] optional_channels = tuple({'id': 'd%d' % i, 'name': 'D%d' % i, 'desc': 'Data line %d' % i} for i in range(NUM_CHANNELS)) annotations = tuple(('c%d' % i, 'C%d' % i) for i in range(NUM_CHANNELS)) annotation_rows = (('items', 'Items', tuple(range(NUM_CHANNELS))),) def __init__(self): self.reset() def reset(self): pass def start(self): self.out_ann = self.register(srd.OUTPUT_ANN) def decode(self): max_possible = len(self.optional_channels) idx_channels = [ idx if self.has_channel(idx) else None for idx in range(max_possible) ] has_channels = [idx for idx in idx_channels if idx is not None] conds = [{idx: 'r'} for idx in has_channels] start_sample = 0 sample_data = None while True: pins = self.wait(conds) if sample_data is not None: self.put(start_sample, self.samplenum, self.out_ann, sample_data); sample_data = None start_sample = self.samplenum try: pin_number = pins.index(1) except ValueError: continue if pin_number != 0: sample_data = [pin_number, [task_names[pin_number]]]
V celom kóde je jediná zaujímavá metóda - decode. V nej sa kontrolujú pripojené vstupy, registruje sa tu wait podmienka spustená pre nábežnú hranu ktoréhokoľvek vstupného signálu a pre udalosti sa generuje signál (self.put).
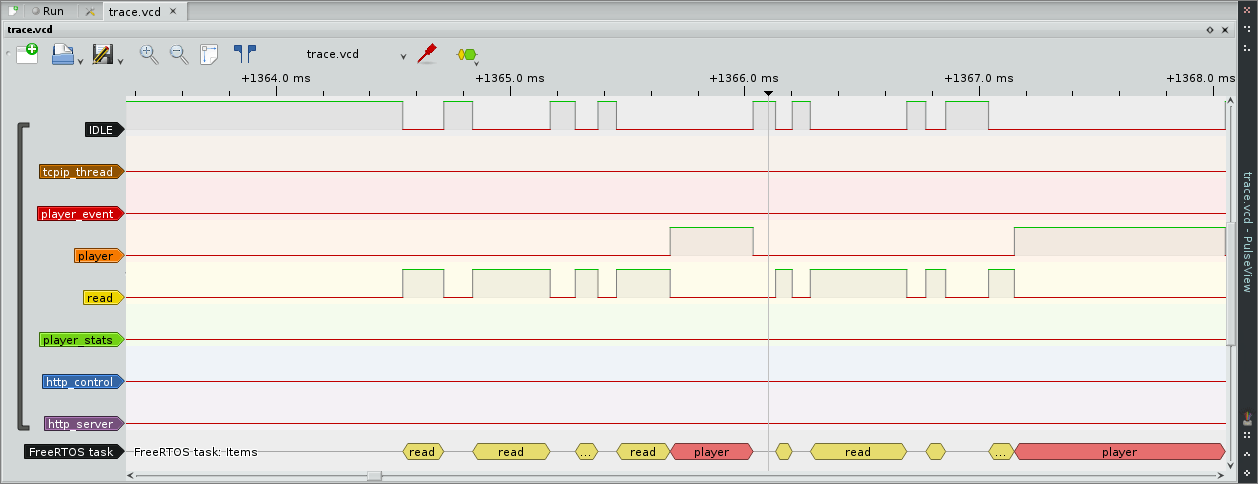
Podčiarknuté a sčítané: sledovať vykonávanie kódu je možné dosiahnuť pri troche snahy aj s OSS softvérom bez nutnosti platiť tisíce dolárov za komerčný softvér.
Nakoniec si ešte trochu rýpnem do embedded vývojárov. Je škoda, že množstvo malých, ale užitočných kúskov softvéru si každá firma rieši interne a nezverejňuje ich ako OSS. Ešte väčšia škoda, že takto sa správajú aj bežní hobby bastliči v Arduine.
Pre pridávanie komentárov sa musíte prihlásiť.

Poznas pre gcc __builtin_bswap??? Preco nenechavas endianitu podla platformy, ale striktne urcujes BigEndianitu. Lepsie prirodzena pre platformu, tak:
. A rovno daj format time_diff. A pripadne v linuxe dat ako parameter programu na zistenie velkost resp. do syslogu mozes dat spravu, ze kolko ma velkost v B. Ak by si to spustal na big endianite linuxe, nebolo by potrebne tu konverziu. Ak to neimplementujes, tak to daj ako poznamku.
Tu zlozene zalozky mas preco?
Nie, ale poznám hton. Kódu špecifickému pre GCC sa vyhýbam.
Pretože formát prenášam medzi rôznymi platformami. Pretože potrebujem najskôr prečítať príznak dĺžky časového záznamu a potom samotný časový záznam. V opačnom poradí by som musel najskôr prečítať čas a potom dĺžku, čo je samozrejme blbosť keď potrebujem najskôr vedieť dĺžku.
Na mojej cieľovej platforme nemám time_diff, ale mám presnejší systémový timer. Ak by som tam aj mal time_diff tak by to bola pekná blbosť pretože time_diff má veľkosť 16B. Dáta, ktoré zaznamenávam majú 1B, takže každý záznam by mal dĺžku 17B. Teraz keď zaznamenávam len rozdiely má väčšina záznamov dĺžku 2-3B, čo je podstatný rozdiel ak to mám pretlačiť cez pomalú sériovú linku.
Pretože som používal ten istý názov premennej path, ale alokoval som ju na stacku s 2 rôznymi dĺžkami.
Pokial mas moznost, pouzi tie (trebars cez podmienku predprocesora), nakokolko vie pouzit prekladac co najefekt. hardver.
Ak to posises v C, lebo pripona .c, tak to pis riadne v cecku - tj. malloc() a free(). Pis co by najlahsie zrozumitelne aj pre inych, ak maju Tvoj kod pouzivat.
Takže mám písať podmienku ak je litle endian, ak je gcc prehoď bity pomocou gcc, ak nie je gcc prehoď bity ručne, ak je big endian neprehadzuj bity? Takže namiesto univerzálneho kódu, ktorý vie kompilátor pekne optimalizovať mám písať 3 rôzne kódy pre ... nejakú virtuálnu výhodu, ktorá však nie je výhodou, lebo generovaný kód bude po prechrúmaní optimalizátorom rovnaký?
Kto rozhoduje o tom, čo je poriadne C-čko? Je nejaká komisia, ktorá rozhodla, že compound statements sú v C zlé?
Takže namiesto alokácie na stacku (jedna inštrukcia, jeden riadok kódu) mám písať malloc, kontrolu na vrátenie NULL, ak bolo všetko v poriadku tak pokračovať, potom nakoniec zavolať free, ktorá trvá niekoľko tisíc inštrukcií? Takže som na začiatku mal šetriť 8 taktov CPU, ale tu nemusím zrazu šetriť?
Takže si to zhrniem. Výhody:
Nevýhody:
Nakoniec ešte malý fragment z dokumentácie k alokátoru pamäte:
Čo tak si najskôr naštudovať základy vývoja embedded zariadení a potom komentovať?
Pekné to máš.
Toto poznáš? To som našiel, keď som trochu hľadal.
Našiel som to, ale rozbehať sa mi nepodarilo.
V poznámkach tam majú napísané, že vyjde nejaký veľký update.
Plánuješ ten tvoj vydať ako samostatný projekt?
EE, všetky tieto veci sú len drobné side projekty ;)
Tak počkáme si týždeň :-)
A niečo pre hodinky s ESP32 nebude? Napr: ESP8266 (sorry za link na číňana). S takýmito hračkami sa teraz roztrhlo vreco, ale najviac ma zaujal nápis že "The power button must be plugged into the 16850 battery ...", tá baterka je oveľa väčšia jak tie hodinky.
TTGO T-Wristband je podstatne krajší, ale nie, neplánujem.
Vkus je individuálna záležitosť. Ale nevadí, ani ja.