AI Prevod Reči na Text. Recenzia. Google Cloud Console
Speech to text, skratka STT.
Najviac podrobne v tomto článku opíšem ako funguje prevod Reči na Text Google Cloud Console. https://cloud.google.com/speech-to-text
Okrajovo budem hovoriť aj o Whisper (speech recognition system) od Open AI, o Microsoft Azure službách a o opačných službách Text to Speech.
Praktické využitie Prevod Reči na Text. Príklady
novinár si môže uľahčiť prácu a prepísať reč na text
uľahčenie práce pri písaní článkov, písaní emailov. Najprv nahráte nahrávku. Potom ju cez AI službu dáte prepísať na text. Potom je to možné ešte nechyť štylisticky upraviť AI. Osobne mám niečo takéto dobre preskúšané a funguje to
Praktické prevodu textu na reč. Príklady
Človek môže čítať články a popri som robiť inú činnosť
hľadanie kontrola preklepov vo vlastných článkoch
najviac sa mi osvedčil offline softvér na Android T2S, veľké škoda, že už nie je aktívne vyvíjaná ale alternatívu som zatiaľ nenašiel
Whisper
Whisper bol open source projekt, ktorý môže fungovať aj Offline a môžete si ho nainštalovať na linuxe. Grafické rozhranie Whisper si môžete stiahnuť tu. Aplikácia pod názvom Speech Note.
Problém Whisperu je to, že už sa nevyvíja, jeho kvalita je slabá a už je to zastaralý softvér.
YouTube
YouTube podporuje prevod reči na text prostredníctvom titulkov. Podmienka je zvoliť jazyk v nastaveniach videa. Presnosť titulkov ale nie je žiadna sláva. Gemini AI čerpá dáta pri videách práce z titulkov, keď sa napríklad opýtate o čom sa v danom videu hovorí. Napr. ak základe AI „zhrň mi obsah videa“.
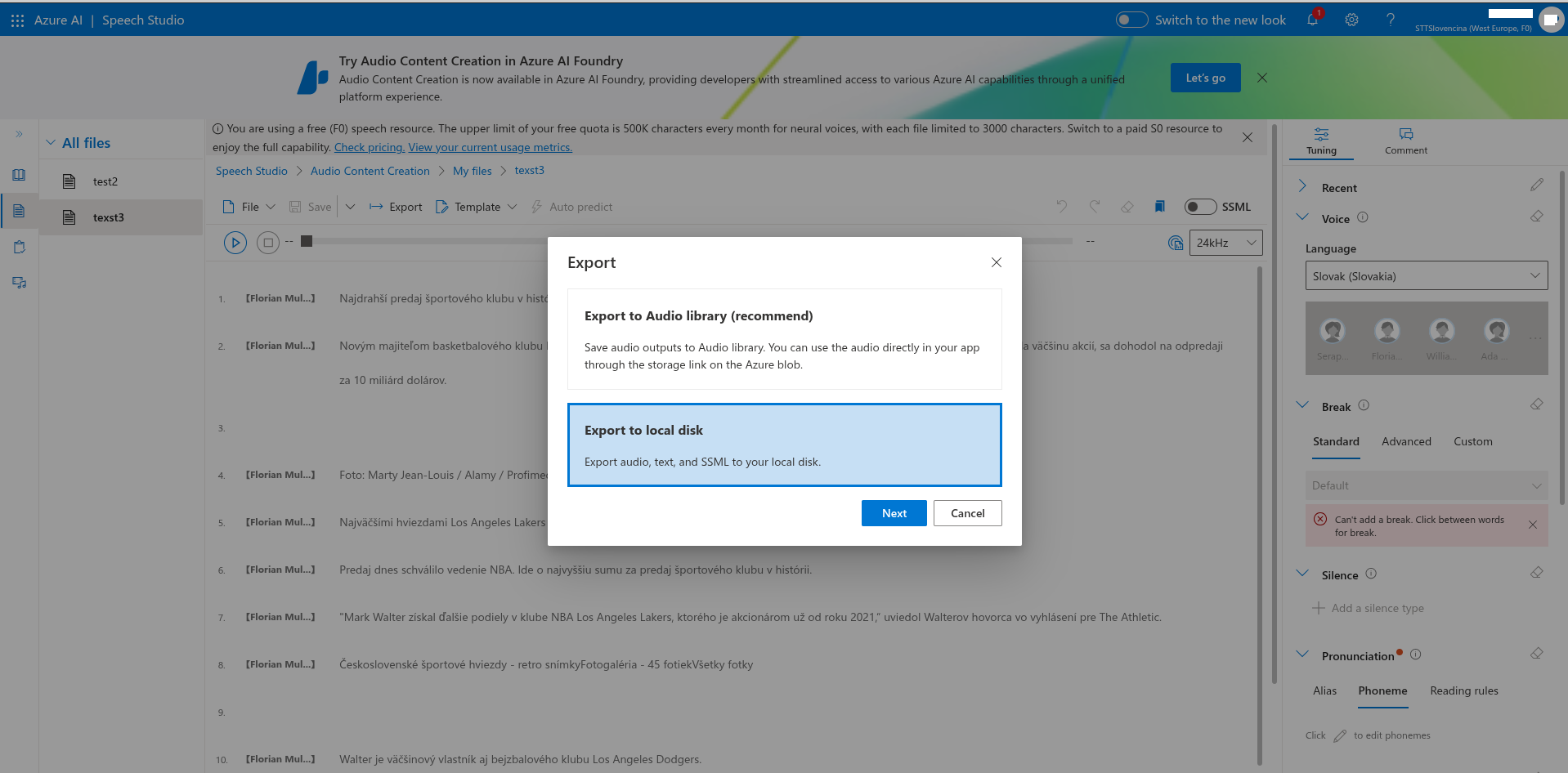
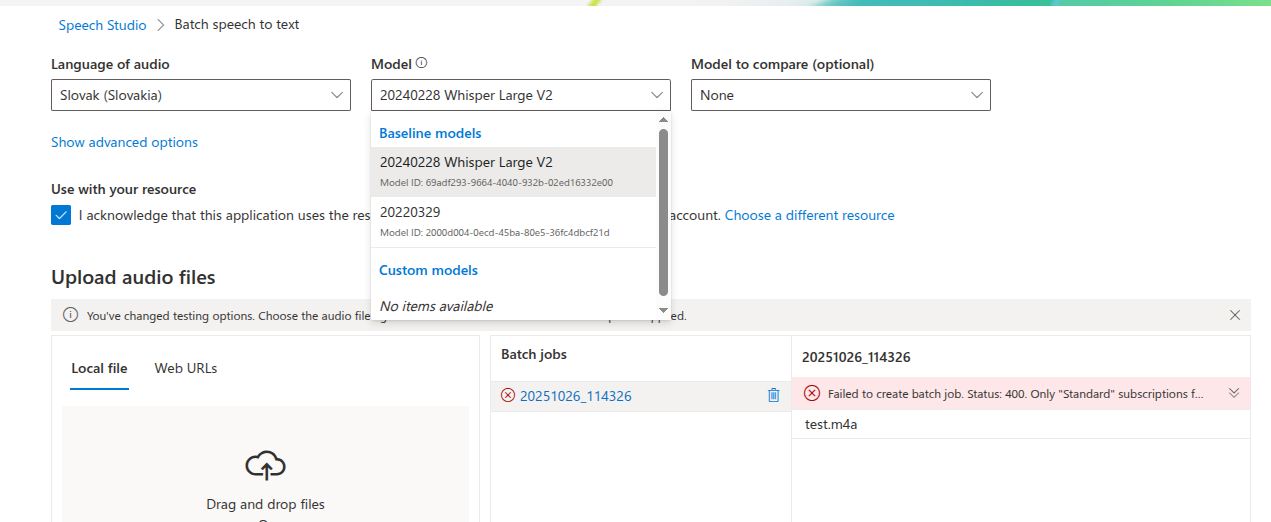
Microsoft Azure
prevod reči na text v slovenčina prakticky nefunguje vôbec.
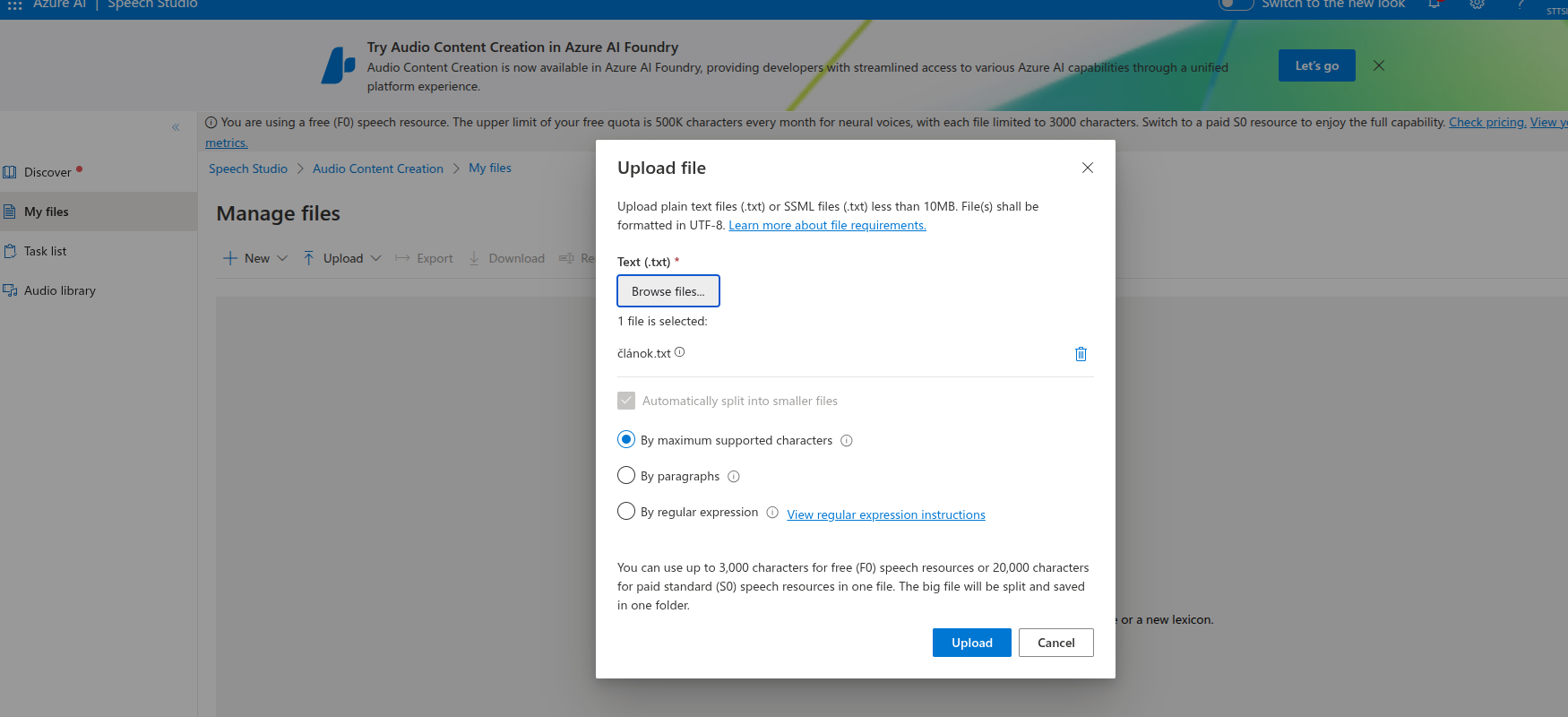
Čo je použiteľné je prevod textu na reč a to aj s grafickým rozhraním. Preto mám v článku viac screenshotov o tejto službe
Aká je cena služby Text to Speech Microsoft Azure? Program zdarma: 0,5 milióna (500 000) znakov mesačne.
Vo free verzii podporuje export TTS textu do audia len do 3000 znakov. Dlhší text vám automaticky rozkúskuje do menších častí, takže potom musíte exportovať do audia každú časť osobitne do viacero audio súborov. Jednotlivé audio súbory môžete zlúčiť pomocou aplikácie LosslessCut
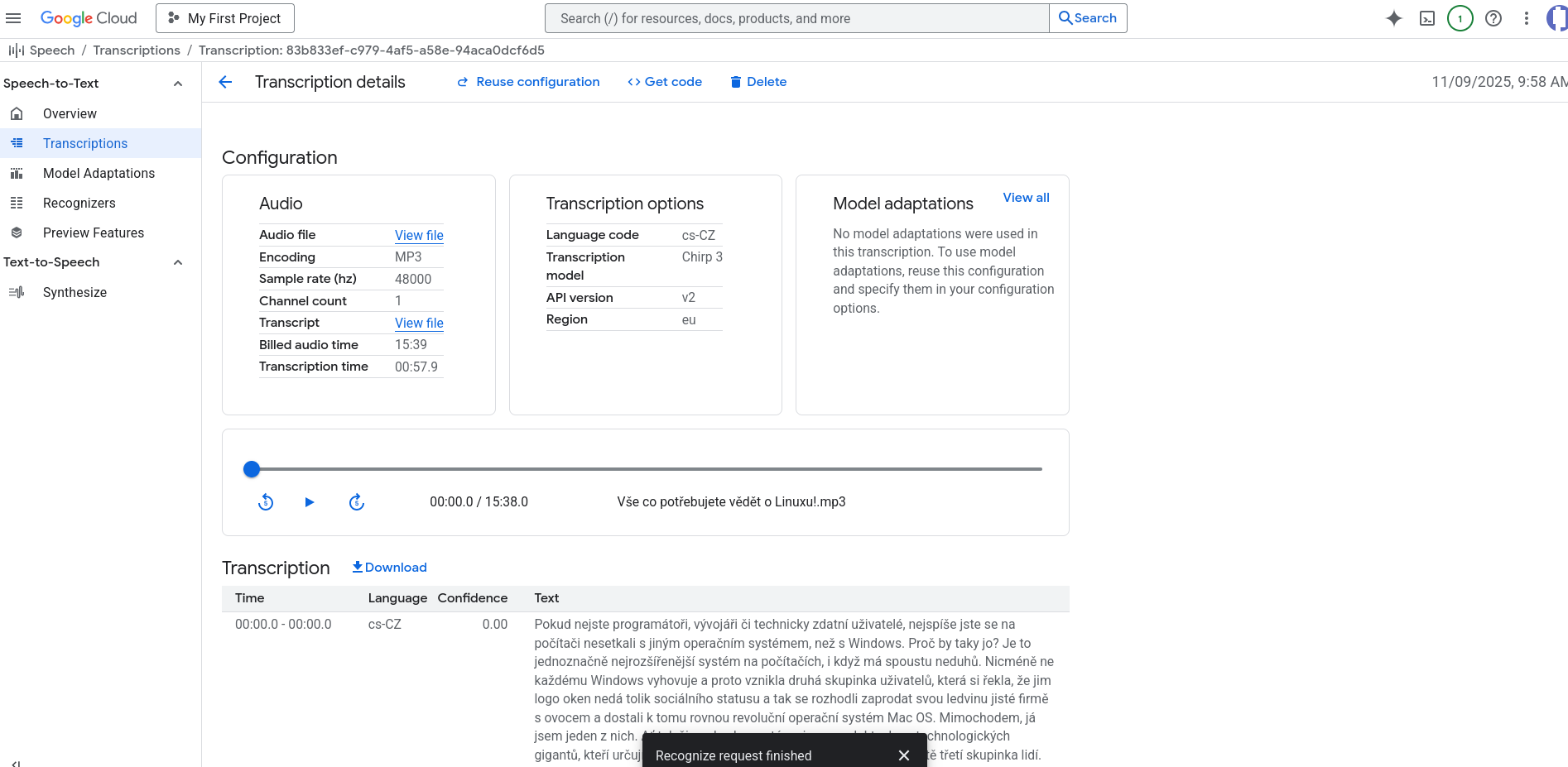
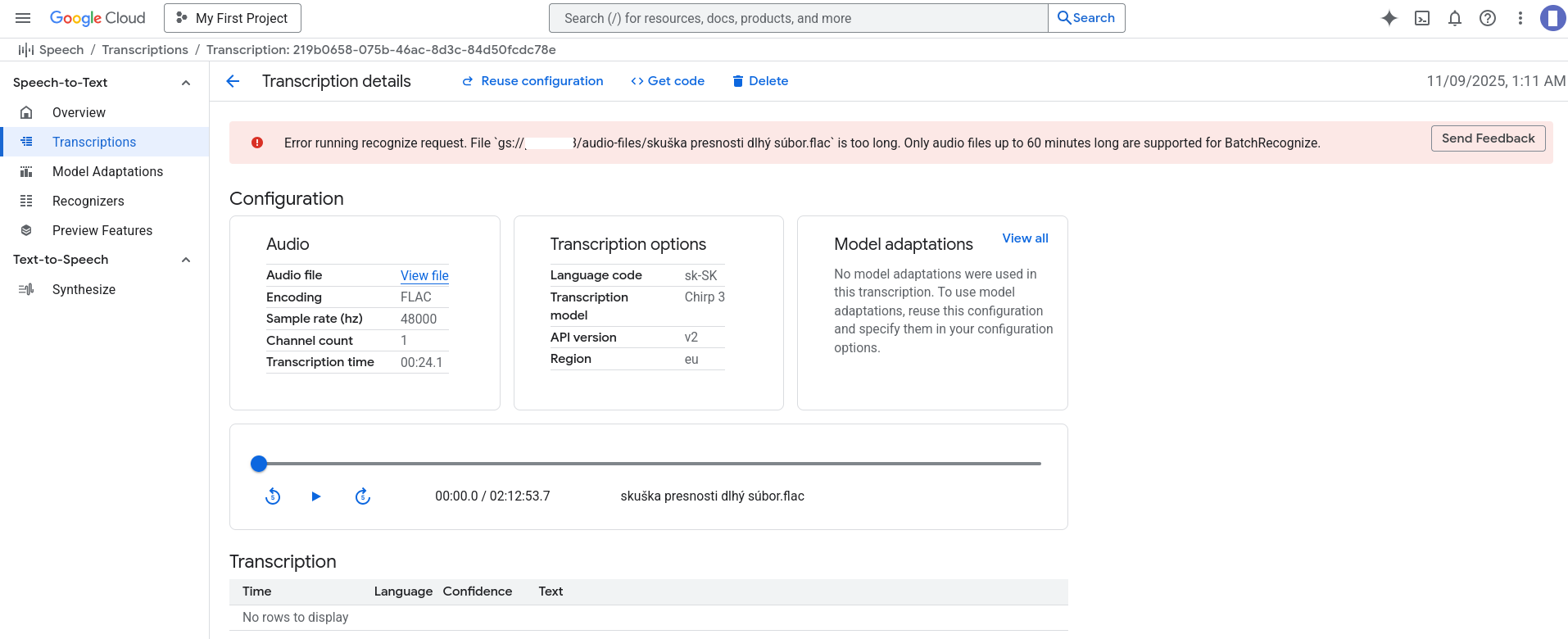
AI prevod Reči na Text. Recenzia. Google Cloud Console
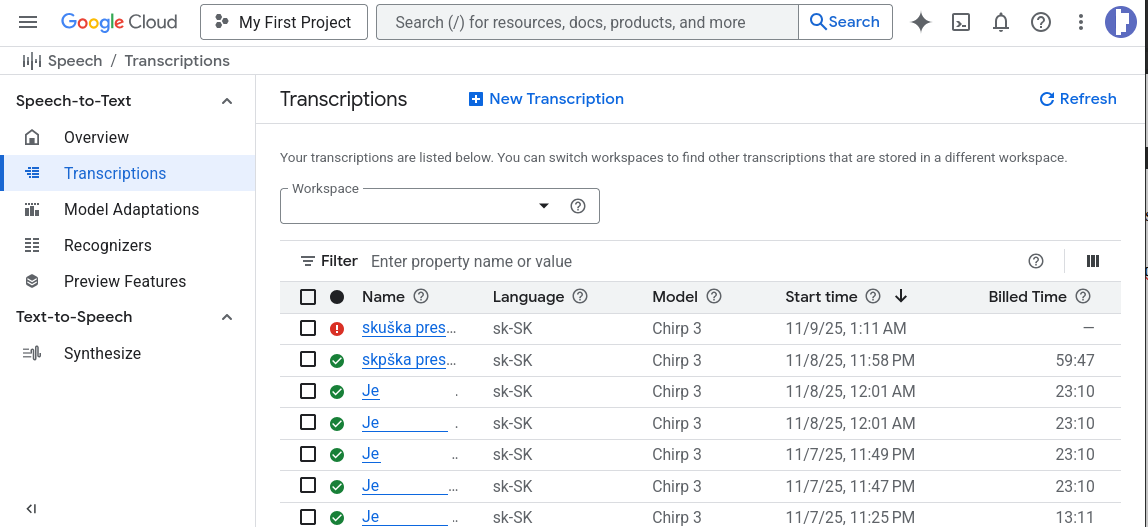
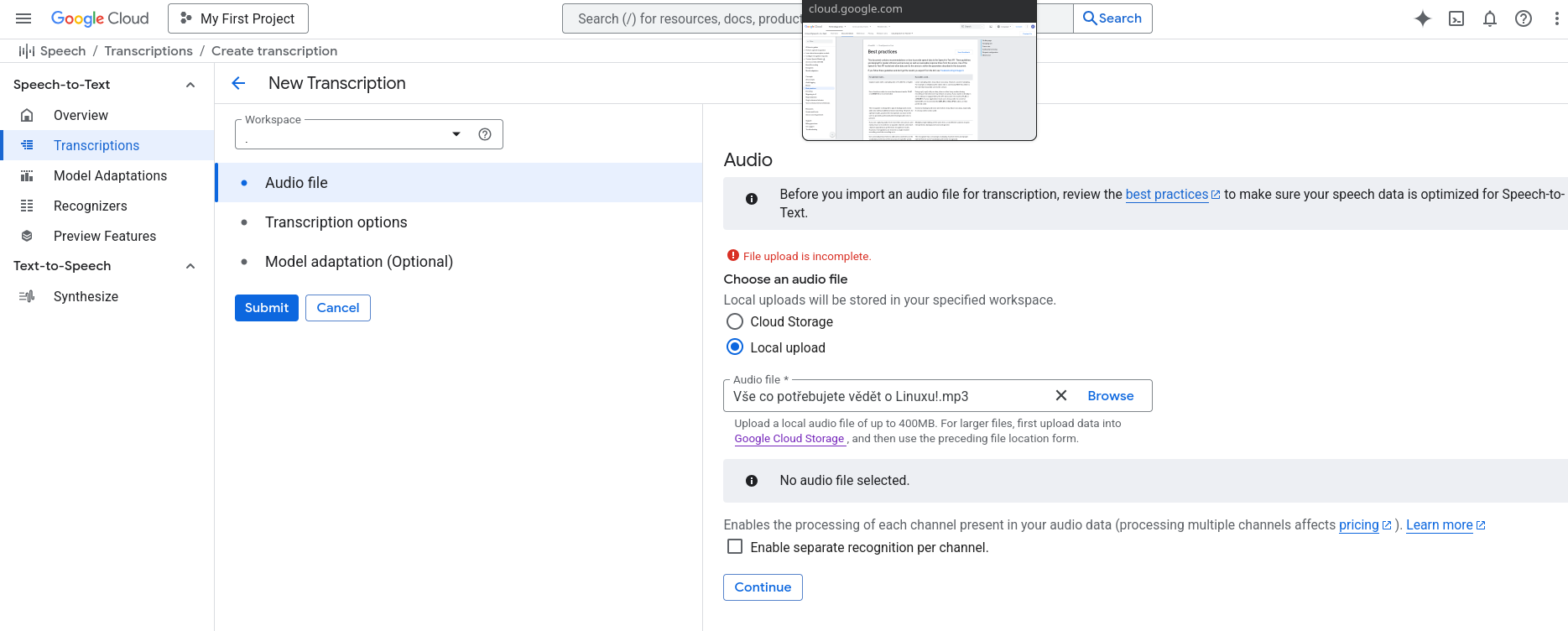
V oblasti služieb prevodu reči na text jednoznačne vyhráva Google Cloud Console.
Podporuje aj dobré grafické rozhranie, nielen API
Vysoká kvalita a nízke ceny, hoci je tam zopár bugov.
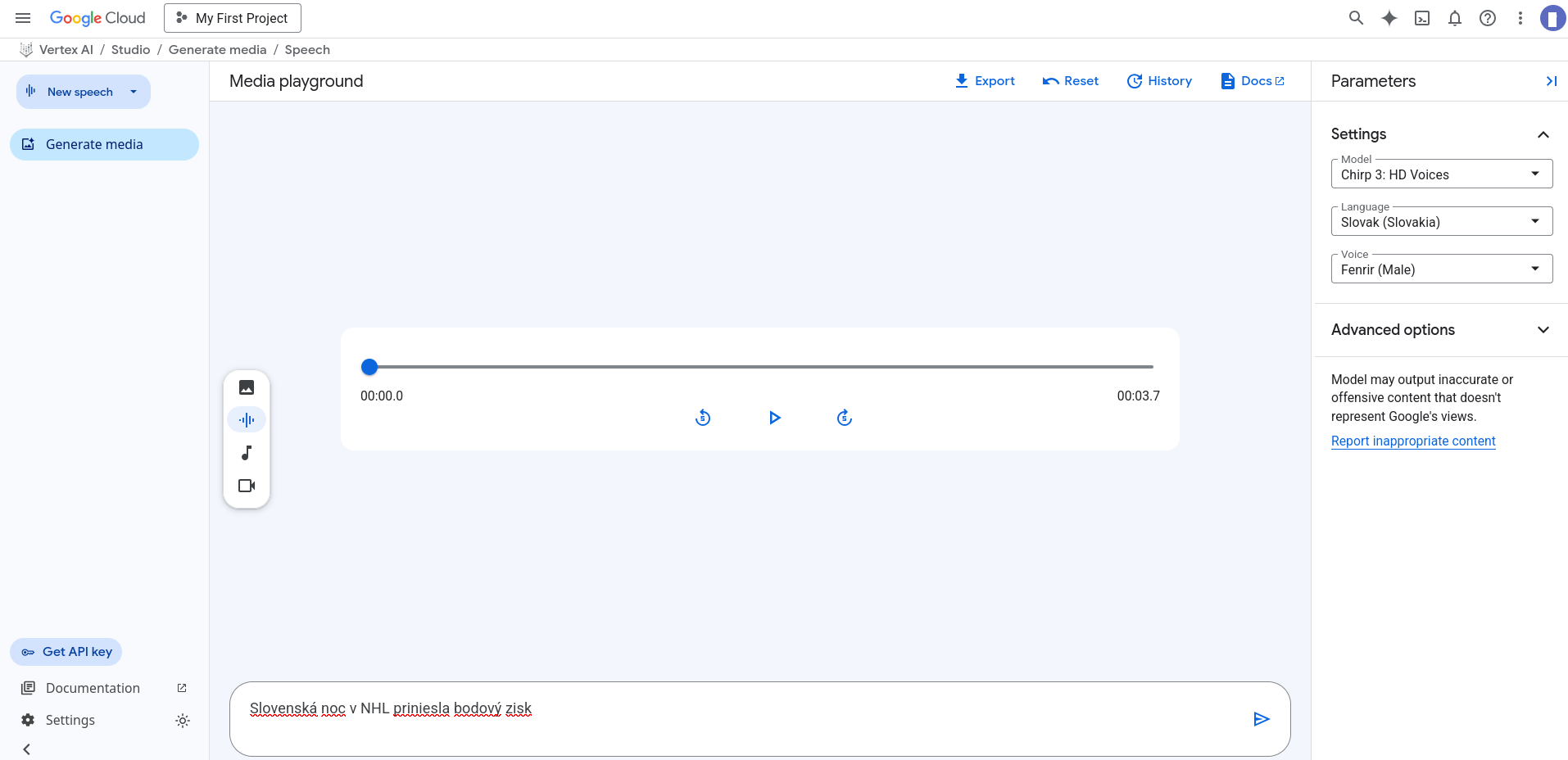
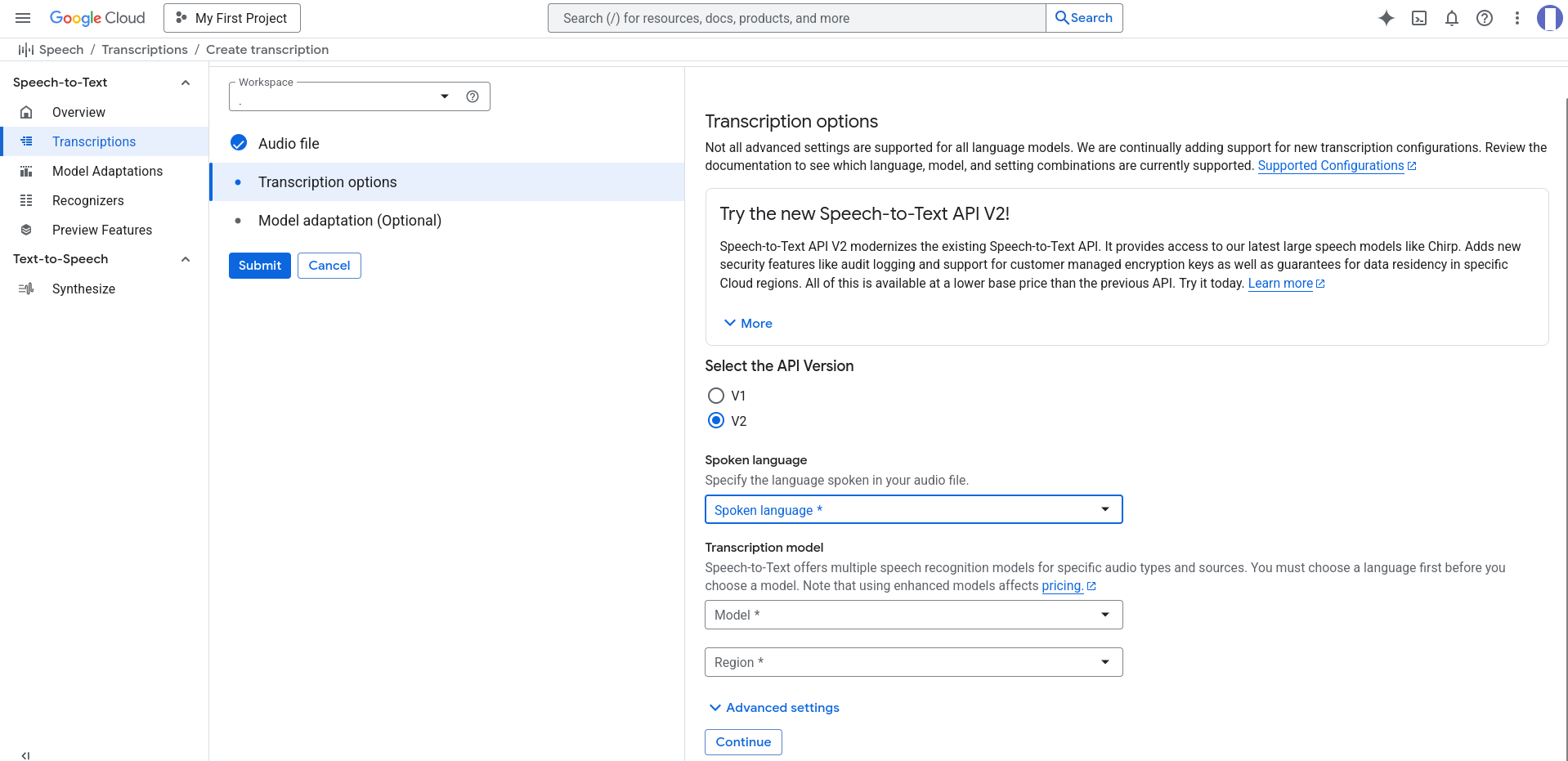
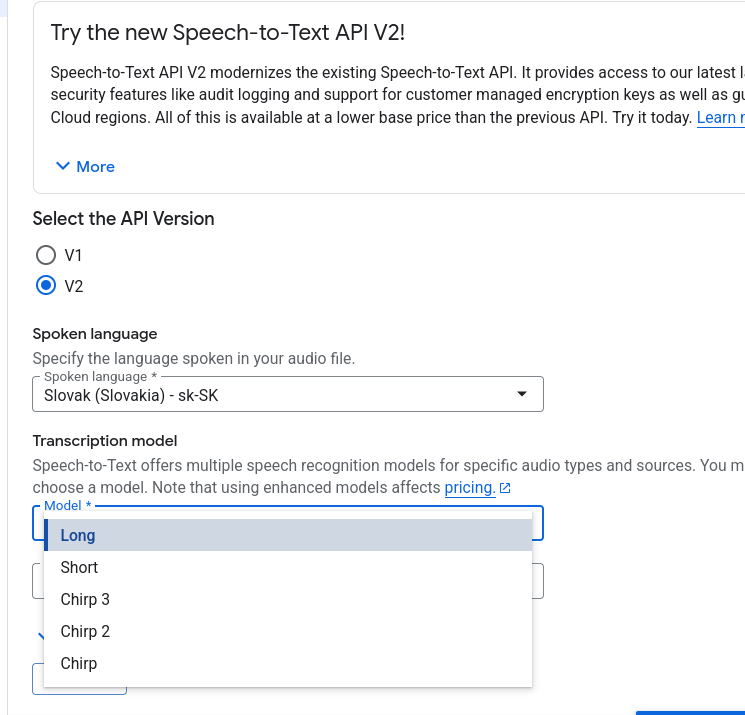
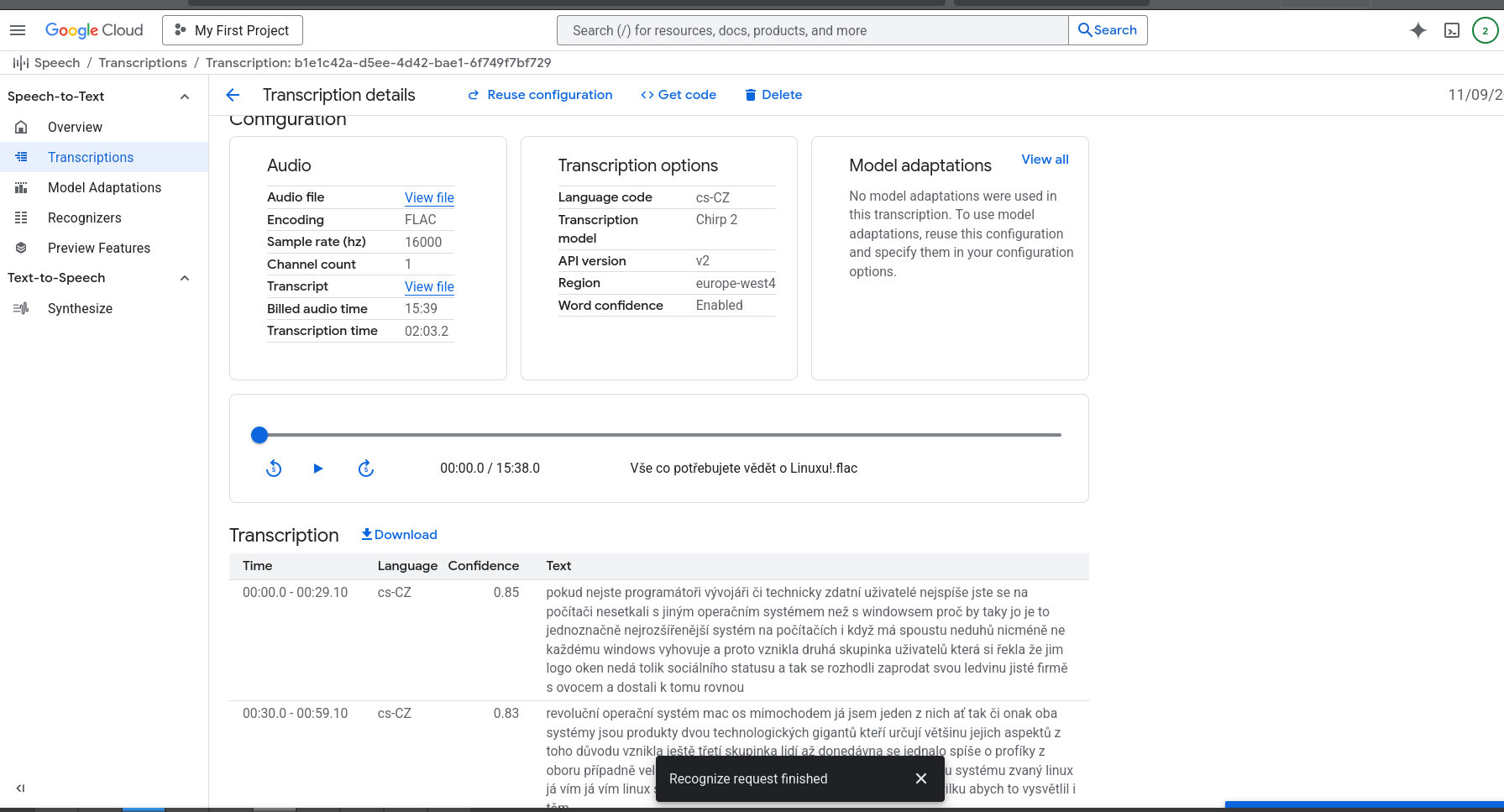
Najviac kvalitný je vývojovo najmladší model Chirp3
jedná sa o AI model ktorý rozumie hovorenému slovu
prvé 3 mesiace je možné službu Google Cloud Console STT využívať zdarma
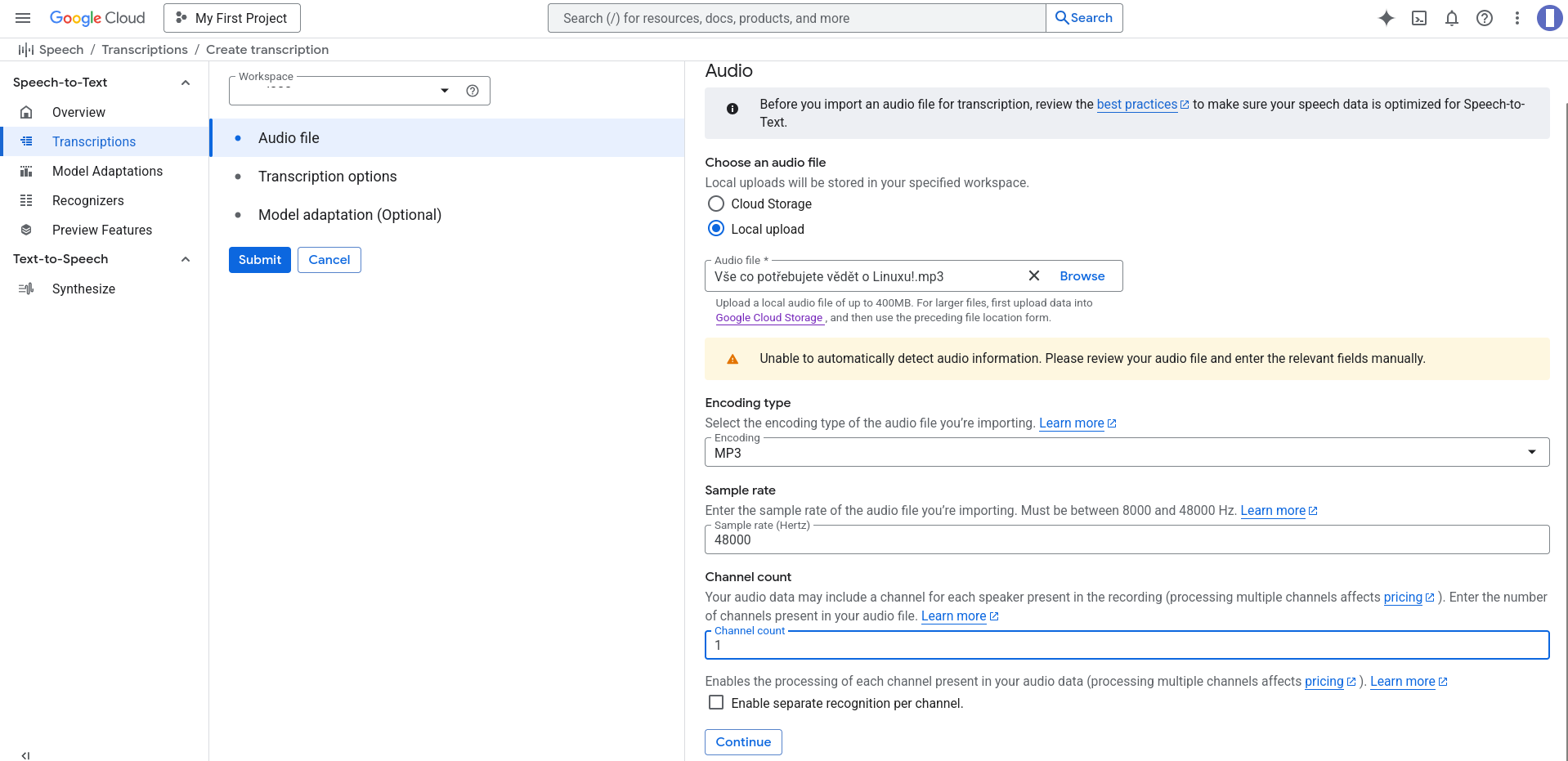
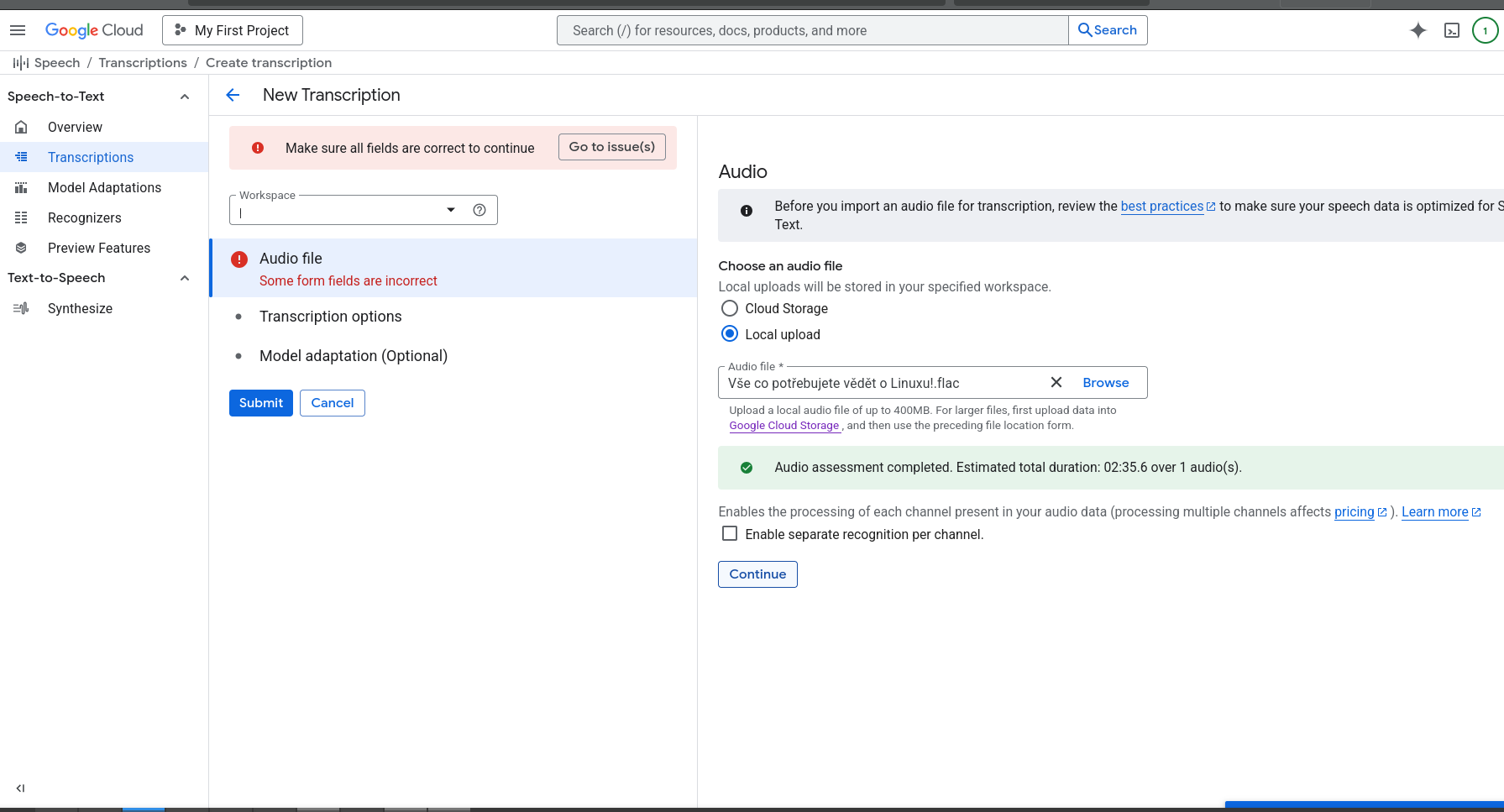
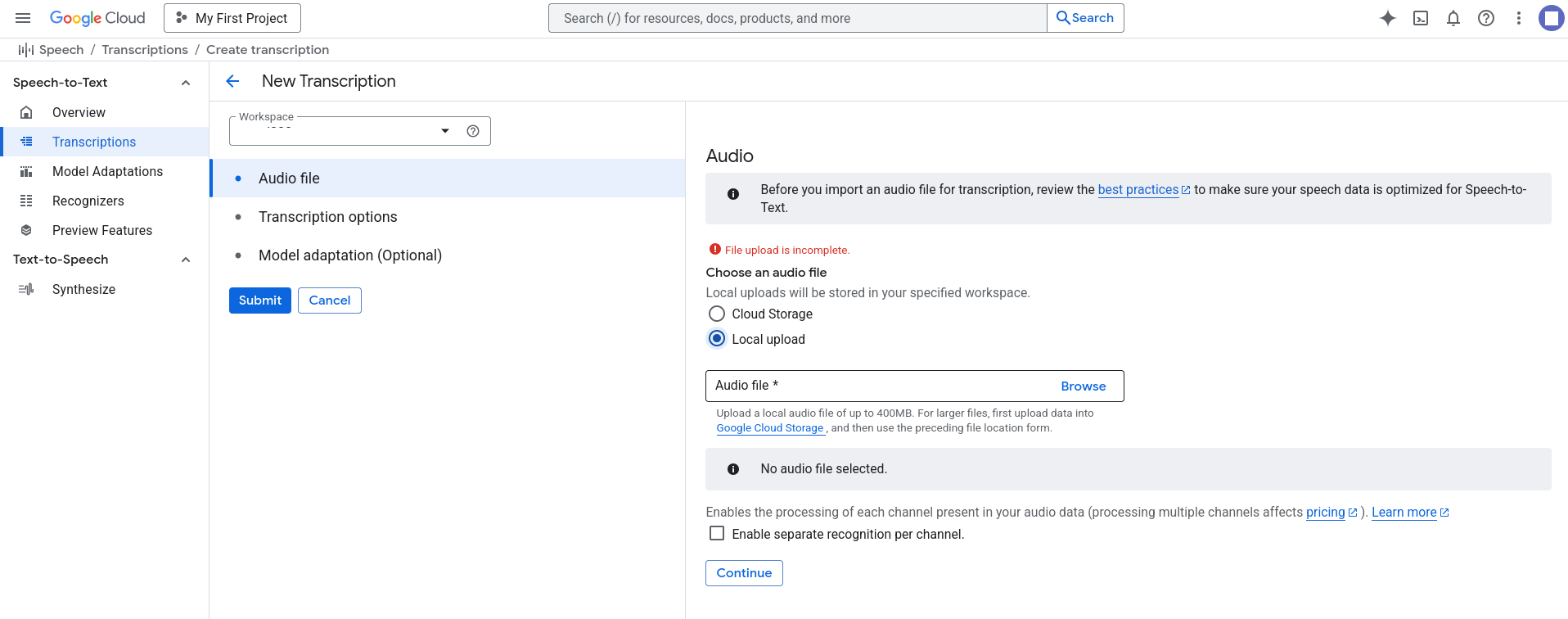
Pre najviac kvalitný prevod reči na text sa odporúča bezstratový formát FLAC, ideálne vzorkovania frekvencia vzorkovacia frekvencia 16000 Hz.
Zaujímavosť: Všimol som si, že keď znížim vzorkovaciu frekvenciu zo 48000 na 16000 Hz, tak audio súbor zaberá oveľa menej na disku.
Ak nemáte audio súbor v bezstratovom formáte, odporúča sa stratový formát prekonvertovať na FLAC
prečo je ten bezstratový formát pre AI tak dôležitý je záhada aj pre mňa. My ľudia nie sme schopní rozlíšiť stratový a bezstratový formát podľa sluchu
keď som testovať presnosť prepisu, tak skutočne keď som nahrával vo formáte FLAC, tak presnosť prepisu bola oveľa lepšia ako v prípade formátu OPUS
najlepší a najmodernejší audio stratový formát OPUS je tiež dobrý pre túto službu, hoci nie je tak dobrý ako FLAC
editácia audio súboru nie je odporúčaná (napríklad použiť rôzne filtre a podobne)
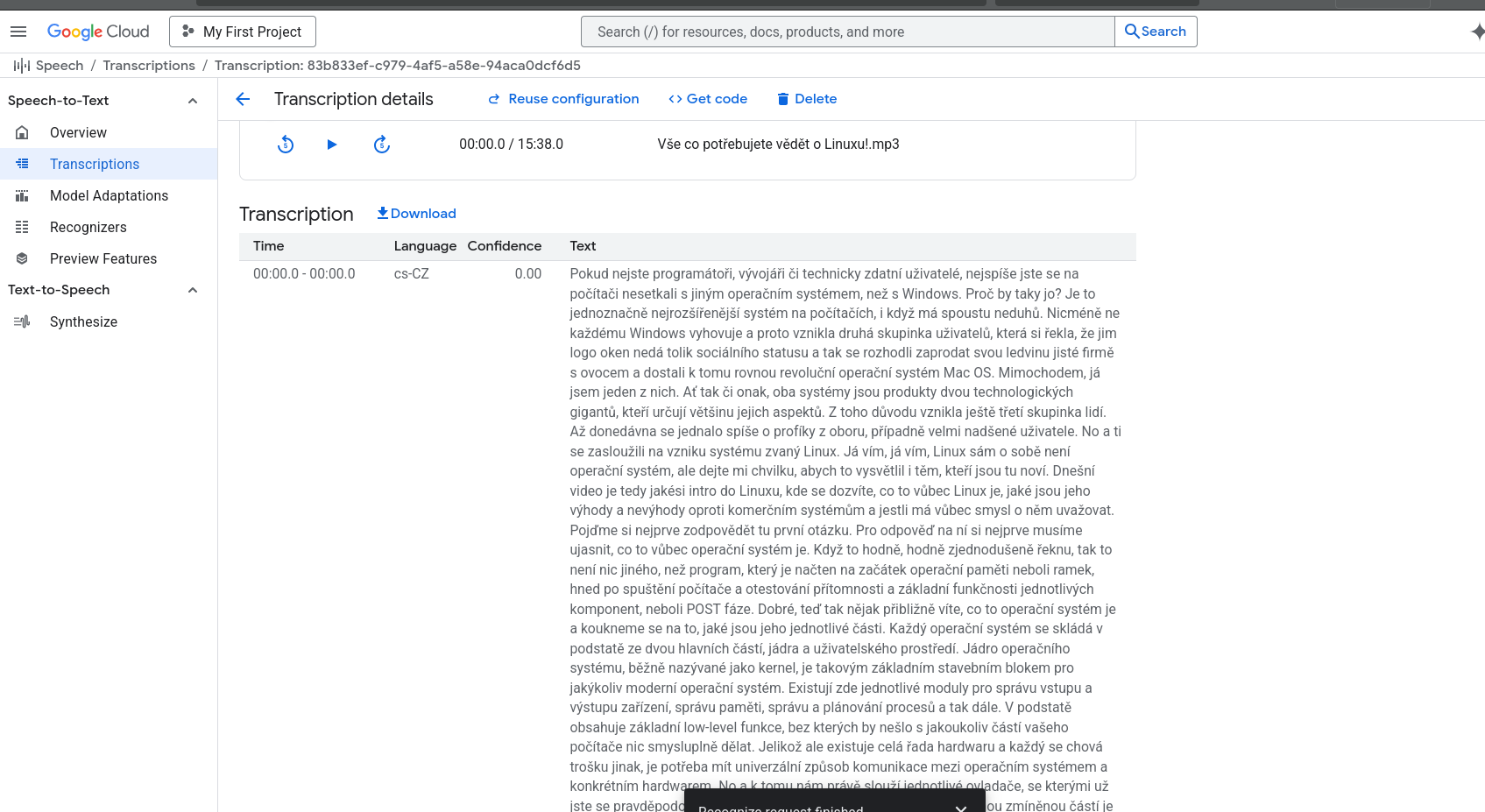
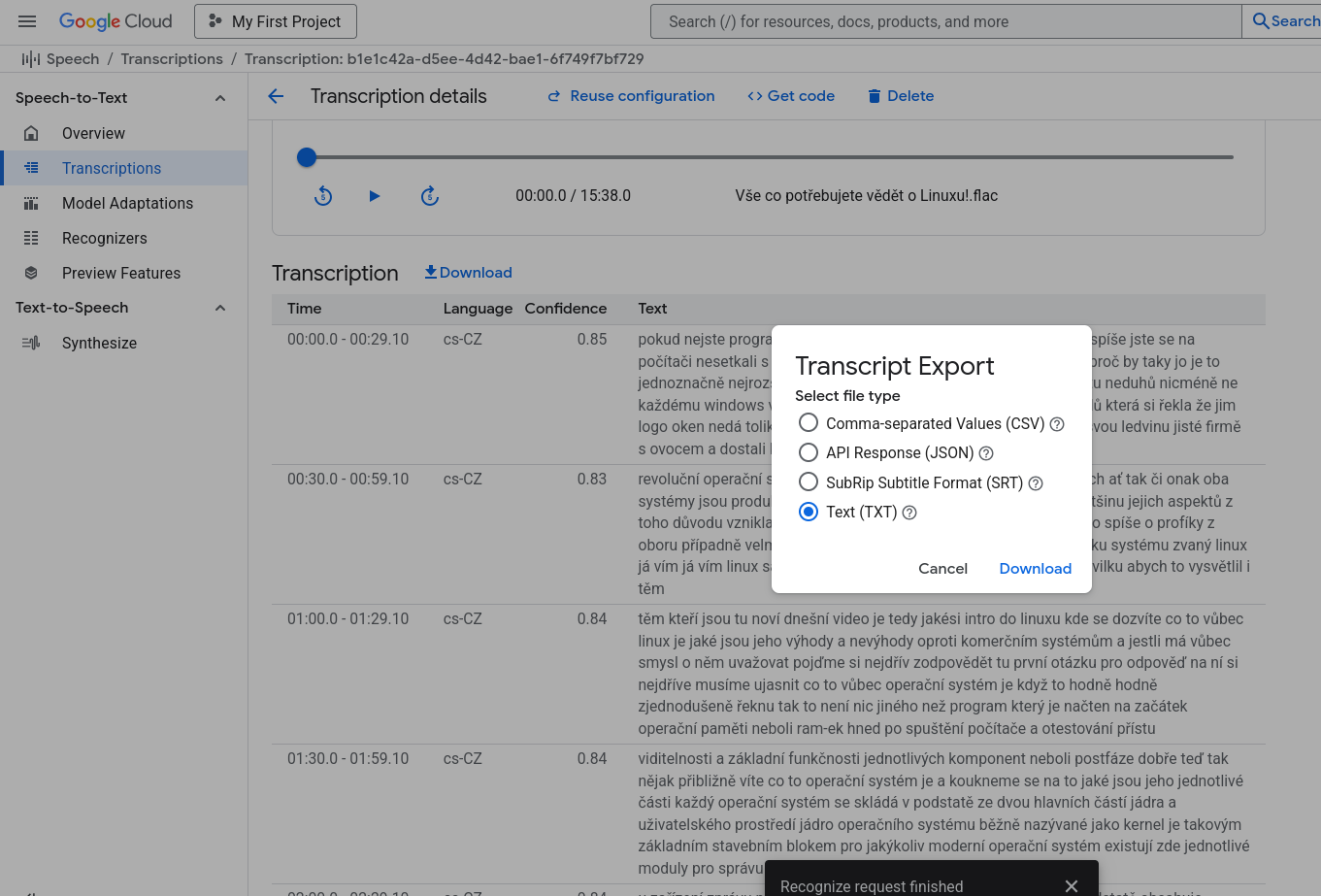
možnosť exportu titulkov (SRT formát). Je to možné prakticky využiť na kvalitnejšie titulky pre YouTube videá, podcasty
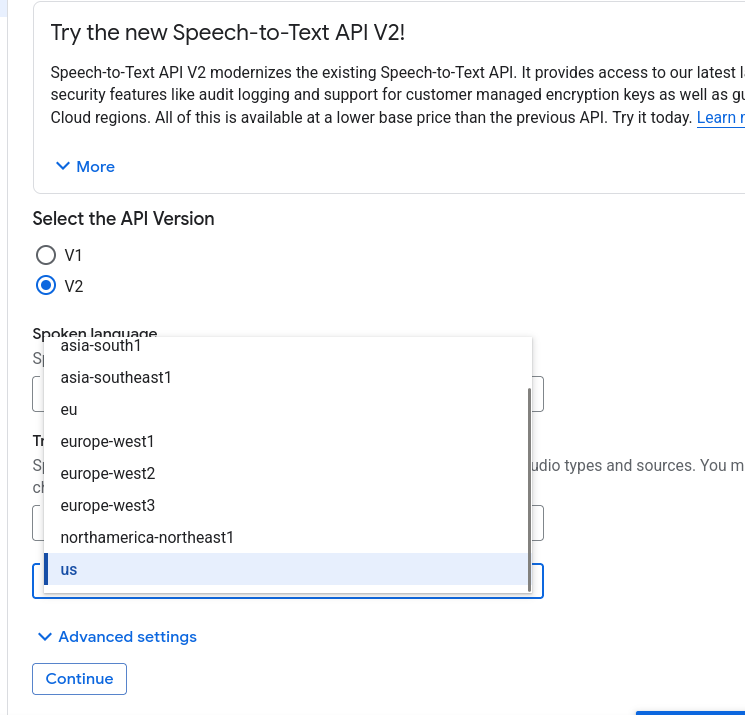
Čo to znamená možnosť europe-west3, europe-west2, eu, europe-west1, v službe Google Cloud STT Chirp 3?
cena približne 0,016 USD za minútu audia. Prvá hodina mesačne zdarma
Bugy Google Cloud Console STT
nesprávna identifikácia začiatku a konca vety. Jednu dlhšiu vetu má tendenciu rozdeliť na viacero krátkych viet, čo niekedy môže nesprávne zmeniť pôvodný význam hovoreného slova, hoci prepis sám o sebe je správny.
prepisy obsahujú sem tam nejaké chyby. Napríklad nesprávne prepis mien známych osobností
v prípade Chirp3 nepodporuje titulky, časové pečiatky. Bug nahlásený už veľmi dlho ale opravy žiadne
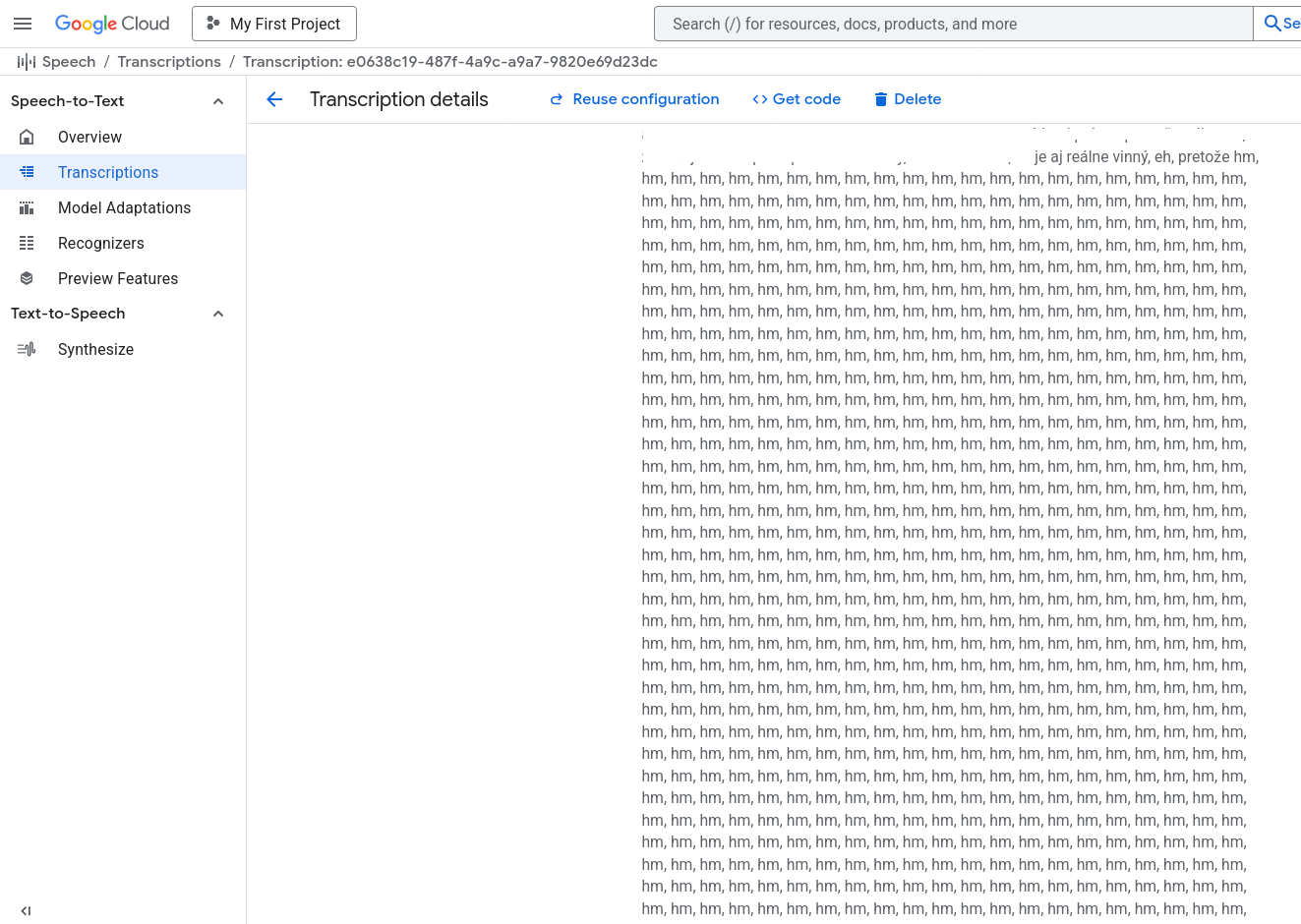
Neodfiltruje zbytočné zvuky alebo „slová“ ako je „eh“, „ehm“, „hm“. Takéto slová by sa po správnosti nemali v prepise nachádzať prípade vstupného audio súboru OPUS. Riešenie je takýto výstup dať ešte opraviť AI. Pri vstupnom súbore FLAC je to lepšie
Chirp3 podporuje len súbory s maximálnou dĺžkou 60 minút, čo je veľmi nepohodlné, ak musí rozdeľovať vstupný audio súbory a následne napájať výstupný text. Zbytočne to zaberie veľa času
Pri vstupnom OPUS súbore AI nerozumie zakoktaniu a výsledný text je nesprávny. Pri vstupnom súbore FLAC je to lepšie
Verím že všetky tieto bugy sa odstránia a o pár týždňov, mesiacov či rokov už nebudú aktuálne
Čo to znamená možnosť europe-west3, europe-west2, eu, europe-west1, v službe Google Cloud STT Chirp 3?
Toto je súhrn všetkých možností, o ktoré ste sa pýtali. Každá z nich predstavuje geografickú lokalitu, kde Google spracuje vašu zvukovú požiadavku.
Výber správnej lokality je kľúčový pre GDPR (ochranu údajov) a rýchlosť (latenciu).
Tu je priame porovnanie všetkých štyroch možností:
| Možnosť | Typ lokality | Geografická poloha | Poloha voči EÚ |
europe-west3 | Región (jedno mesto) | Frankfurt, Nemecko | Vnútri EÚ |
europe-west1 | Región (jedno mesto) | Belgicko (St. Ghislain) | Vnútri EÚ |
europe-west2 | Región (jedno mesto) | Londýn, Spojené kráľovstvo | Mimo EÚ (po Brexite) |
eu | Multi-región | Viaceré mestá v rámci EÚ | Vnútri EÚ (garantovane) |
Zaujímavosť: bezstratový formát
AI som zadal otázku prečo je pri prevode Reči na Text pre AI dôležité to aby bol vstupný audio súbor v bezstratovom formáte FLAC. Koho zaujímajú detaily, môže si prečítať aj túto odpoveď AI. Pre mňa to bolo veľmi zaujímavé.
Toto sú výstupné informácie z chatu s AI:
Ďakujem za vynikajúcu otázku a veľmi relevantné pozorovanie! Vaša skúsenosť s lepšou presnosťou transkripcie pri použití FLAC oproti OPUS pre Google Cloud Speech-to-Text (STT) je presne to, čo očakávame, a nie je to žiadna záhada. Hoci ľudské ucho nemusí rozlišovať medzi týmito formátmi, pre umelú inteligenciu, ktorá analyzuje zvuk, je rozdiel zásadný.
Pozrime sa, prečo je to tak a na akom princípe to funguje:
Čo je to bezstratový (FLAC) a stratový (OPUS) formát?
- Bezstratový formát (napríklad FLAC, LINEAR16/WAV) : Tieto formáty komprimujú zvukové dáta bez straty akejkoľvek informácie. Keď dekomprimujete súbor FLAC, získate presne tie isté digitálne zvukové dáta, aké boli na začiatku. Je to ako zabaliť súbor do ZIP archívu – veľkosť sa zmenší, ale všetky pôvodné dáta sú tam. Pre AI to znamená, že má k dispozícii kompletnú a neporušenú informáciu o zvuku.
- Stratový formát (napríklad OPUS, MP3, AAC) : Tieto formáty komprimujú zvukové dáta tým, že eliminujú určité informácie , ktoré sú považované za menej dôležité pre ľudské ucho. Algoritmy stratovej kompresie analyzujú zvuk a odstraňujú frekvencie alebo detaily, ktoré ľudia ťažko počujú (napríklad veľmi vysoké alebo veľmi nízke frekvencie, tiché zvuky prekryté hlasnejšími). Vďaka tomu sú súbory oveľa menšie, ale originálne dáta sa nedajú úplne obnoviť .
Prečo je pre AI dôležitý bezstratový formát (FLAC)?
Tu sú kľúčové dôvody, prečo Speech-to-Text dosahuje lepšie výsledky s bezstratovými formátmi:
- Viac dát pre presnú analýzu:
- AI vs. Ľudské ucho: Model STT nie je ľudské ucho. Hoci naše uši ignorujú niektoré frekvencie a detaily, AI model ich aktívne používa na rozlišovanie jemných rozdielov v reči. Dokáže analyzovať celé frekvenčné spektrum a dynamické nuansy zvuku.
- Jemné fonetické detaily: Rozpoznávanie reči je založené na identifikácii foném (základných zvukových jednotiek reči). Tieto fonémy sa prejavujú ako veľmi špecifické vzory vo frekvenčnom spektre a časovej osi zvuku. Stratová kompresia môže tieto jemné, ale pre AI kritické fonetické detaily narušiť alebo úplne odstrániť.
- Odolnosť voči šumu a rušeniu:
- Ľudský mozog filtruje: Náš mozog je mimoriadne dobrý v odfiltrovaní šumu a zameraní sa na reč.
- AI potrebuje čisté dáta: Pre AI je každý šum a rušenie dodatočná informácia, ktorú musí spracovať a odlíšiť od reči. Ak stratová kompresia už "zahladila" alebo "rozmazala" pôvodnú reč a zároveň zosilnila artefakty kompresie, pre AI je oveľa ťažšie oddeliť reč od pozadia. Bezstratové dáta poskytujú AI čistejšiu "zvukovú krajinu" na analýzu, čo jej umožňuje lepšie sa sústrediť na rečové komponenty.
- Väčšia robustnosť pri spracovaní:
- Kompresné artefakty: Stratové formáty zavádzajú tzv. kompresné artefakty – skreslenia, ktoré nie sú súčasťou pôvodného zvuku. Pre AI sú tieto artefakty "nové dáta", ktoré musí interpretovať, a často vedú k chybám.
- Modelový tréning: Modely STT sú trénované na obrovských množstvách zvukových dát. Hoci niektoré modely môžu byť trénované aj na dátach so stratovou kompresiou, vždy dosiahnu lepšie výsledky, keď majú k dispozícii najvernejšiu možnú reprezentáciu pôvodného zvuku.
- Kompatibilita a jednoduchosť:
- Google odporúča FLAC a LINEAR16, pretože sú to overené a široko podporované bezstratové formáty, ktoré poskytujú najlepšiu kvalitu vstupných dát pre ich modely. Použitie týchto formátov zaručuje, že model dostane dáta v takom stave, v akom sú preň najľahšie spracovateľné a optimalizované.
Záver
Rozdiel v presnosti medzi FLAC a OPUS pre Speech-to-Text nie je záhadou, ale dôsledkom rozdielneho prístupu k spracovaniu zvuku. Hoci ľudia nemusia počuť rozdiel, AI model Speech-to-Text profituje z úplnej informácie, ktorú bezstratový formát ako FLAC poskytuje. Táto úplná informácia umožňuje AI presnejšie identifikovať fonémy, lepšie sa vyrovnať so šumom a vyhnúť sa skresleniam spôsobeným stratovou kompresiou, čo v konečnom dôsledku vedie k výrazne vyššej presnosti transkripcie.
Prílohy
- Chirp_2_Vše_co_potřebujete_vědět_o_Linuxu.srt (17.6 kB)
- Chirp_3_..._Vše_co_potřebujete_vědět_o_Linuxu.txt (16.8 kB)
- Google_Vertex_AI_export_audio.flac (266.9 kB)
- Microsoft_Azure_export1.flac (453.4 kB)


Pre pridávanie komentárov sa musíte prihlásiť.