Zlý vtip menom async v djangu (pythone)
Práce na asynchronnom Djangu začali okolo roku 2020. Je rok 2025. Čo tak sa pozrieť, čo sme za tú dobu získali?
Päť rokov je v oblasti IT veľmi dlhá doba aby async prestal ignorovať aj taký technologický konzervatívec a spiatočník ako ja. Po všetkých tých fantastických blogoch a benchamrkoch som nasadol na vlnu asyncu.
Nie až tak dávno som začal nový projekt v asynchrónnom frameworku FastAPI. Nebudem rozoberať, prečo som sa rozhodol práve pre Django v úlohe ORM. Akonáhle som sa začal trocha hrabať vo vnútornostiach, šokovalo ma ako zle všetko funguje. Tento blog bude o čistom djangu.
Výkon
Blogy sľubujú výkon. Tak moje konzervatívne skostnatené ja si spustí zastaralý uWSGI a oproti tomu postavím uvicorn. Oba s jedným workerom. Môj naivný view vyzerá ako väčšina dnešných benchmarkov. Veď prečo sa pozerať na komplexnú aplikáciu keď môžeme merať nič?
from django.http.response import JsonResponse
def naive_sync(request):
return JsonResponse({"status": "ok"})
async def naive_async(request):
return JsonResponse({"status": "ok"})
S týmto viewom si spustím benchmark pre 10 simultánnych požiadaviek a 1000 celkovo:
ab -n 1000 -c 10 'http://127.0.0.1:8000/naive/sync/'
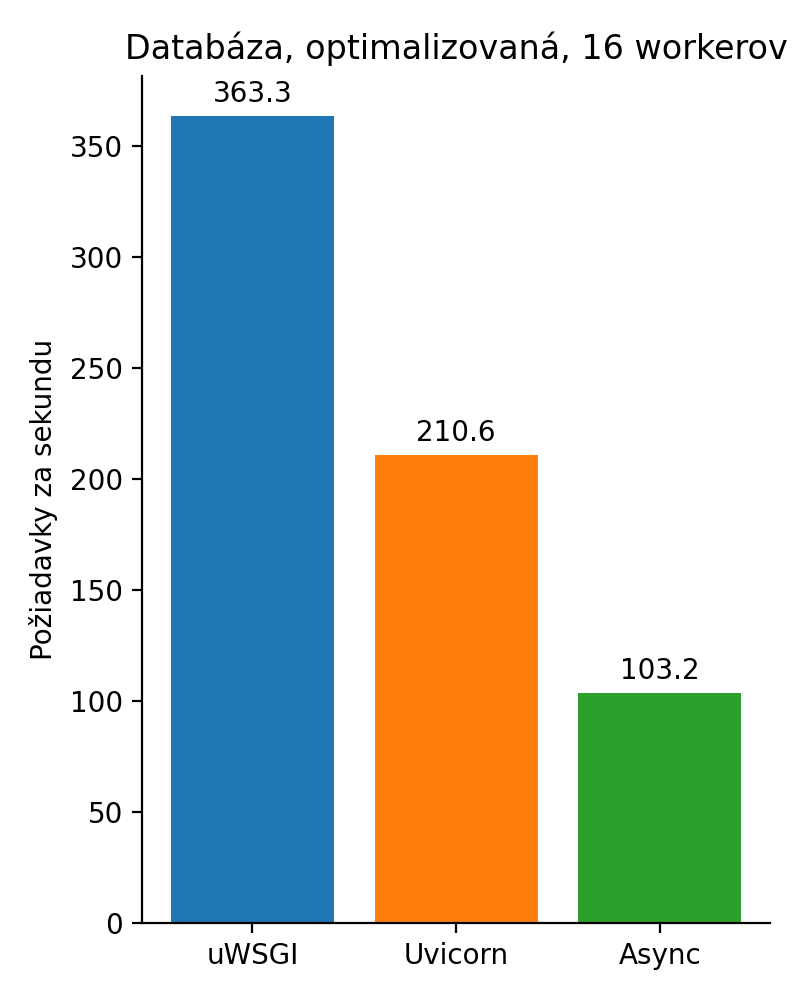
Výsledný graf zobrazuje synchrónne volanie v uWSGI, potom synchrónne uvicorn a asynchrónne uvicorn. Vyššie číslo udáva vyššiu priepustnosť.
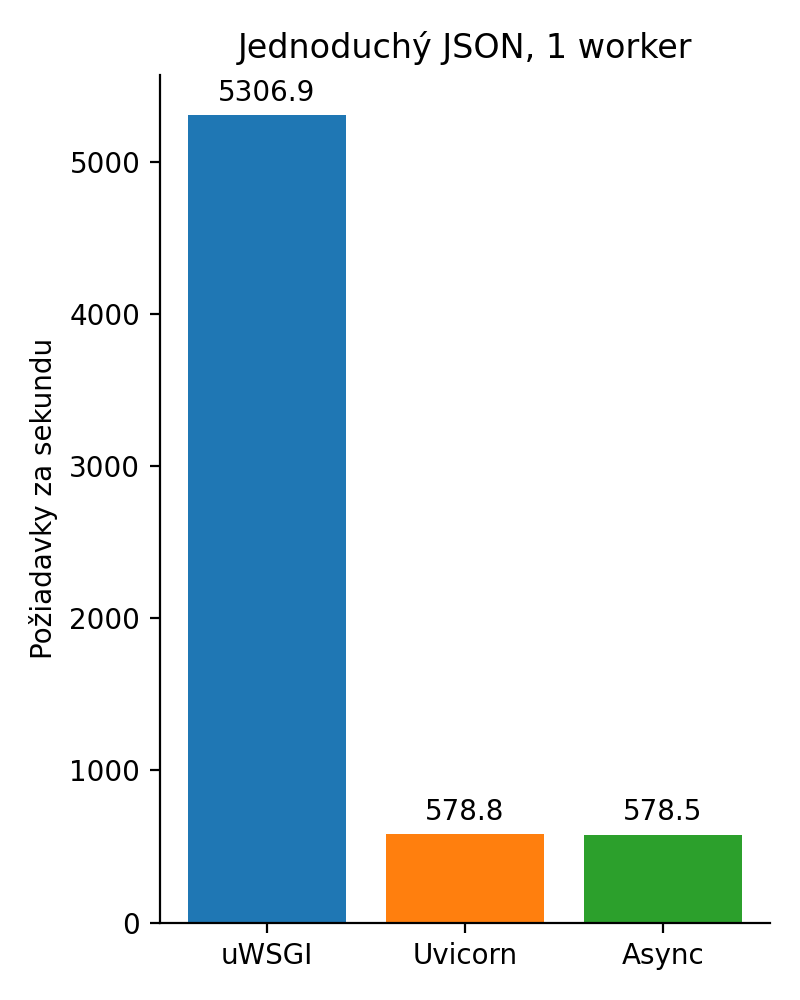
Čo sa stalo? No jednoducho v tomto príklade nemala ako vyniknúť asynchrónnosť. Okrem toho uWSGI je napísaný v C, ale oproti python implementácii je to rozdiel len 2ms na požiadavku. Nie je to nič, čo by mi žily trhalo v reálnej aplikácii. Tento benchmark je nanič a som si toho vedomý.
Chceme ešte jeden nanič benchmark? Samozrejme! Tak teda to isté so 16 workermi.
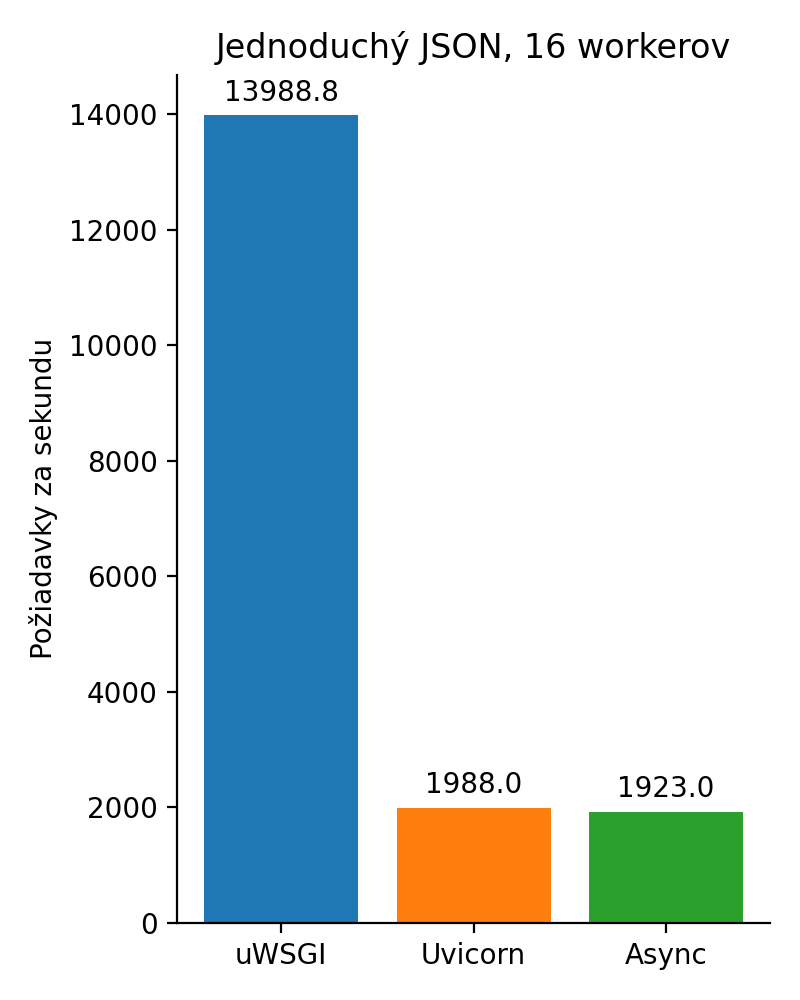
Trocha realistickejší príklad
Väčšina aplikácií hrabe do databázy a tak si vytvorme pár tabuliek:
from django.db import models
class Author(models.Model):
name = models.CharField(max_length=100)
class Category(models.Model):
name = models.CharField(max_length=100)
class Document(models.Model):
name = models.CharField(max_length=100)
authors = models.ManyToManyField(Author, related_name='documents')
category = models.ForeignKey(Category, on_delete=models.CASCADE, related_name='documents', null=True)
Po naplnení databázy som ešte napísal jeden synchrónny a jeden asynchrónny view.
from asgiref.sync import sync_to_async
from django.http.response import JsonResponse
from .models import Document
def db_sync(request):
data = []
for document in Document.objects.order_by('pk'):
authors = []
data.append(
{
"name": document.name,
"category": document.category.name,
"authors": authors,
}
)
for author in document.authors.all():
authors.append({"name": author.name})
return JsonResponse({"data": data})
async def db_async(request):
data = []
async for document in Document.objects.order_by('pk'):
authors = []
data.append(
{
"name": document.name,
"category": (await sync_to_async(getattr)(document, 'category')).name,
"authors": authors,
}
)
async for author in document.authors.all():
authors.append({"name": author.name})
return JsonResponse({"data": data})
Vytvoril som dve prakticky rovnaké funkcie líšiace sa len v dvoch detailoch. Prvým je volanie generátora for. V jednom prípade je synchrónny (for) a v druhom prípade asynchrónny (async for). No a potom je tu táto šialenosť:
(await sync_to_async(getattr)(document, 'category')).name
Python neumožňuje kombinovať synchrónne a asynchrónne funkcie. Napíšete jedinú funkciu asynchrónne a musíte prepísať všetky funkcie, ktoré ju volajú. V postate tým infikujete celý kód. Ak ste tvorcom knižnice, môžete buď napísať knižnicu synchrónne, alebo asynchrónne, alebo oboma spôsobmi pričom každú funkciu napíšete 2x a bude sa v 99% prípadov líšiť v tomto:
# async async def afunkcia(): ... await ainafunkcia() ... # sync def funkcia(): ... inafunkcia() ...
Django začala ako synchrónna knižnica a postupne sa duplikuje kód. Niektoré „drobnosti“ nie sú doteraz podporované ako napríklad transakcie. No a potom sú tu ešte veci, ktoré sa nedajú prepísať ako napríklad property, kde .category potrebuje zavolať SQL dotaz, ale propery nie je polymorfná a tak volá len synchrhónny select, ktorý sa nedá zavolať z asynchrónneho kontextu. Zabalíme to teda do sync_to_async
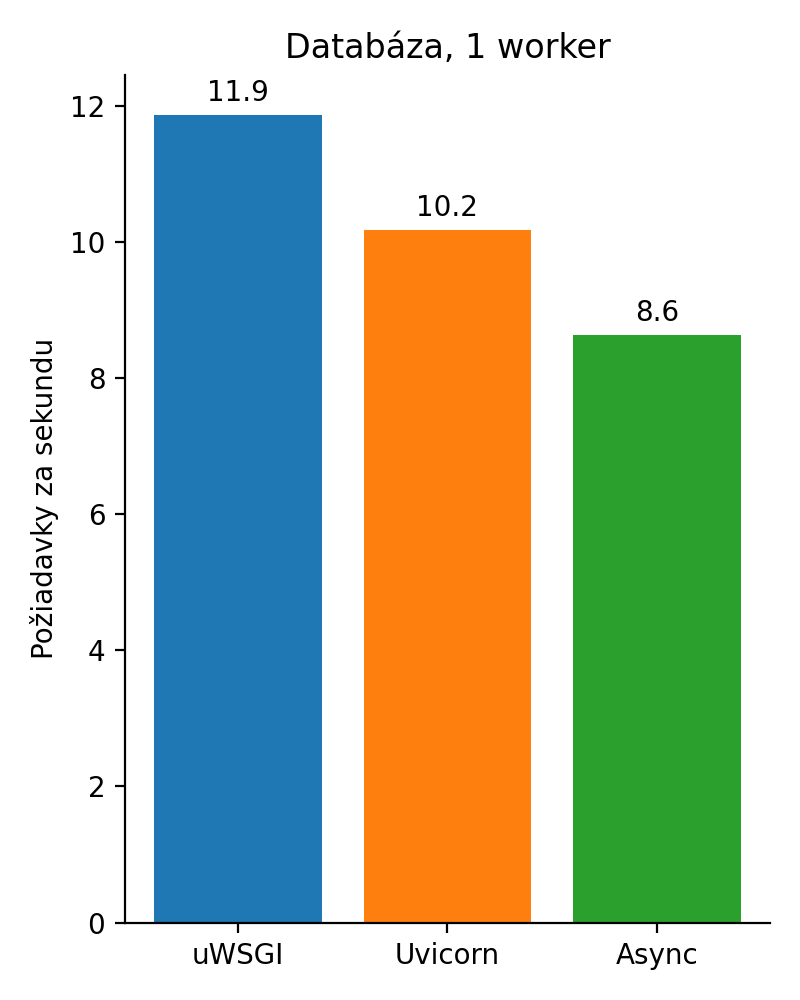
To nie je možné!?! Dajme tam 16 workerov. Nech sa ukáže asynchrónnosť.
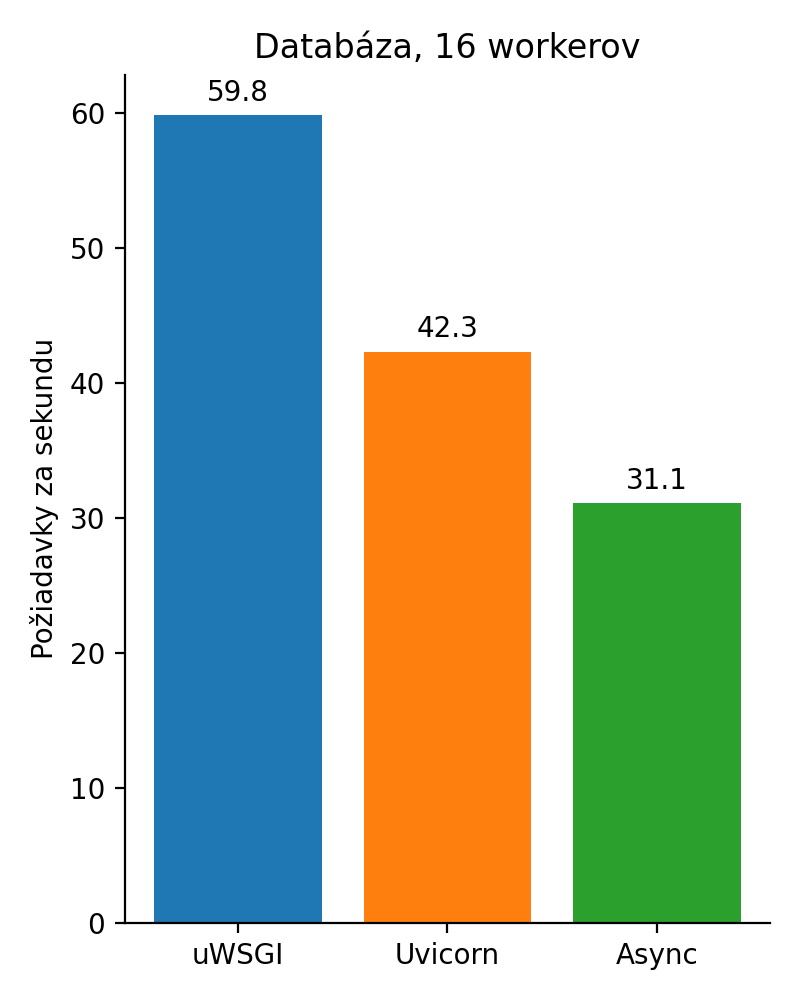
Ešte väčšia katastrofa, čo? Rozmeňme si to na drobné. Databázový driver, ktorý django používa je synchrónny. Aj keby nebol, tak celá implementácia Djanga je hračkárska a vyzerá takto:
async def aget(self, *args, **kwargs):
return await sync_to_async(self.get)(*args, **kwargs)
V tomto momente dochádza k prepnutiu kontextu, čo môže trvať rádovo okolo 1ms. Nie je dostatok vývojárov, aby implementovali a udržiavali Django so skoro každou duplikovanou funkciou. Preto sa len hráme na akože asynchrónnosť. Mimochodom viete, že veľa vývojárov vo svojich knižniciach overriduje save, aby tam pridali napríklad nejakú logiku, ja neviem date_created = now? Teraz to funguje pretože asave vyzerá takto: sync_to_async(self.save). Teraz si predstavte ako sa django knižnice začnú rozpadávať až sa začne reálne implementovať async. Celý ekosystém, desaťtisíce knižníc sa musia prepísať.
Nakoniec ešte doplním úpravu vďaka ktorej sa spustia len 2 dotazy namiesto 300:
def db_opt_sync(request):
data = []
for document in Document.objects.order_by('pk').prefetch_related('authors').select_related('category'):
authors = []
data.append(
{
"name": document.name,
"category": document.category.name,
"authors": authors,
}
)
for author in document.authors.all():
authors.append({"name": author.name})
return JsonResponse({"data": data})
async def db_opt_async(request):
data = []
async for document in Document.objects.order_by('pk').prefetch_related('authors').select_related('category'):
authors = []
data.append(
{
"name": document.name,
"category": (await sync_to_async(getattr)(document, 'category')).name,
"authors": authors,
}
)
async for author in document.authors.all():
authors.append({"name": author.name})
return JsonResponse({"data": data})
Záver
Čo som vlastne chcel povedať? Neverte všetkým sladkým rečiam v blogoch. Python má svoju filozofiu „explicit is better“ a nej podriadil aj implementáciu async. Autori knižníc sa teraz musia rozhodnúť, či budú písať synchrónne, asynchrónne, alebo budú svoj kód duplikovať, budú mať 2x viac práce a 2x viac chýb. Pritom v dynamickom jazyku s tak neskorou adaptáciou async / await nebolo farbenie vôbec nevyhnutné. Škoda. Z môjho pohľadu premárnená príležitosť urobiť lepší jazyk.
Pre pridávanie komentárov sa musíte prihlásiť.

Je to nádherný článok — hoci pre úzku skupinu čitateľov. Hoci je Python asi najrozšírenejší, toto je predsa len vyššia škola.
K poslednej vete článku: Ono je to takto s každým jazykom. Nejaká idea na začiatku je poplatná dobe, paradigme a technológii. Potom sa po čase ukáže, že ešte to a tamto by bolo prínosom, ale už existuje milión knižníc a ich implementácií.
Viď Java. Hoci je teraz tuším v. 25, tak najrozšírenejšia je asi 21, a stále hojne používaná je 11 i 8. Lebo — kto by prepisoval fungujúci kód.
Nehovoriac o bankových či leteckých systémoch, stále bežiacich na COBOLe.