Emacs - Org - LaTeX - triky #2
V minulej časti sme si čo-to povedali, ako generovať LaTeX dokument pomocou org módu pre GNU Emacs. Dnes si ukážeme, ako zadávať unicode znaky, špeciálne symboly a vyhodnocovať kód priamo v dokumente.
Fonty v LaTeX-u
Ich implementácia nie je úplne triviálna. Užívateľ textových procesorov si pomerne ľahko do systému nainštaluje nové/iné fonty (typicky nakopírovaním do ~/.fonts/) a ľahko ich aj aplikuje. Vlastne - je asi aj ťažko predstaviteľné, že toto môže byť vôbec nejaká téma na článok alebo diskusiu.
Začnem z jednoduchšej strany: ak používame na generovanie PDF z LaTeX zdrojových kódov renderer LuaLaTeX alebo XeTeX, tak je to jednoduchšie - oba dokážu pracovať z OTF i TTF fontami. Akurát stačí do preambuly zadať \usepackage{fontspec} a následne napríklad príkazom \setmainfont{<meno_rodiny_fontu>} tento font zvoliť či prepínať.
Napriek tejto zjavnej výhode sa intenzívne používa starší pdflatex. Tento je často rýchlejší pri spracovaní dokumentov, má dlhšiu históriu a je široko používaný v akademickej komunite, čo znamená, že existuje veľké množstvo dostupných balíkov a dokumentácie. Ďaľej je menej náročný na pamäť a CPU. A akosi je stále zaužívaný. A je stále výborný. Hoci práca s fontami je trochu… obskurná.
PdfLaTeX
Nemusíme ísť veľmi do detailov. Len spomeniem, že fonty sú kombináciou viacerých súborov, osobitne sú uložné metriky (teda rozmery) a glyfy (konkrétny obrazec). Tzn. že napríkad OTF font musí byť konvertovaný a upravovaný. Navyše adresárová štruktúra je tiež pomerne komplikovaná, typicky sa skladá z podadresárov (systémových alebo užívateľských) v texmf/fonts ako napríklad texmf/fonts/enc (obsahuje súbory s kódovaním), texmf/fonts/map (metadáta pre fonty), a iné. LaTeX využíva systém pre vyhľadávanie fontov, ktorý obsahuje niektoré preddefinované cesty a adresáre, kde sú fonty uložené.
Napríklad fontawesome5 má takútu adresárovú štruktúru:
$ tree -d fontawesome5 fontawesome5 ├── doc ├── enc ├── map ├── opentype ├── tex ├── tfm └── type1 8 directories
Takže ide to, samozrejme, len je proste iné.
Najčastejšie používané fonty ako Computer Modern (predvolený font LaTeXu, založený na dizajne Donalda Knutha, široko používaný v akademickej sfére, najmä v oblasti matematiky a vied), známy pätkový Times, bezpätkový Helvetica, serifový Palatino, klasický Arial a nakoniec krásny Latin Modern (ktorý je modernizovanou verziou Computer Modern). A tieto fonty obsahujú kopec glyfov, ku ktorým sa dá pristupovať pomocou príkazu LaTeX-u.
A teda nie vložením unicode znaku.
Čože? To je trochu,… no sto rokov za opicami, či nie?
A veru nie. Treba si uvedomiť poslanie LaTeXu - konzistencia v typografii. LaTeX je navrhnutý na vytváranie typograficky prepracovaných dokumentov. Použitie príkazov LaTeXu zabezpečuje, že sa znaky budú správne reťaziť a vzhľad každého symbolu bude harmonizovaný s ostatnými prvkami dokumentu. Toto sa zatiaľ nedarí v bežných textových procesoroch, aj keď neskúsené oko to vidieť nemusí. Ďalej LaTeX ponúka výkonné prostredie pre formátovanie matematických výrazov. Príkazy ako \arrow sú často súčasťou zložitých matematických vyjadrení a pomocou LaTeXu je možné písanie a formátovanie týchto výrazov rýchlejšie a intuitívnejšie. Pri používaní LaTeXu je zaistené, že rovnice a symboly vytvorené pomocou LaTeXu budú vyzerať rovnako na rôznych zariadeniach a platformách. S Unicode môže dôjsť k nekompatibilite alebo zmenám v zobrazení v závislosti od použitého písma alebo softvéru. No a nakoniec - LaTeX má širokú komunitu a množstvo balíkov, ktoré umožňujú používanie špeciálnych symbolov, písmen a štýlov, ktoré nie sú dostupné v Unicode.
Náhľad na niektoré znaky, ako ich vo svojom latexovníku uviedla známa osoba československého sveta LaTeX-u - Rudolf Blaško - https://frcatel.fri.uniza.sk/~beerb/latex/
 |
| Obr. 1: Niekoľko z nepreberného množstva symbolov. |
No ale kto si má toto pamätať, že áno? Že \Sigma vykreslí Σ? A komu sa chce hľadať po fórach a tabuľkách?
Naštastie existuje šikovný nástroj - TeXmatch, v ktorom stačí myšou znak nakresliť a dostaneme príslušný príkaz. Na toto som si spravil i funkciu v Emacse:
(defun latex-glyph-detect (&optional arg) "Run Tex-match for finding glyph" (interactive) (shell-command (concat "/home/richard/.prog/texmatch/tex-match.linux.amd64 &" )) (delete-other-windows))
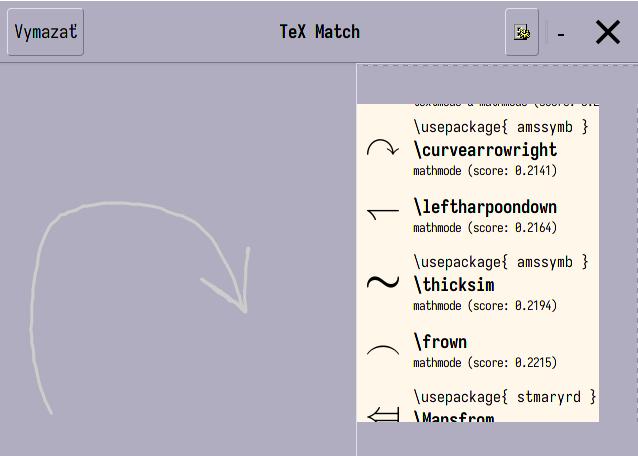 |
| Obr. 2: TeXmatch v akcii. |
Podobný online nástroj je i na https://detexify.kirelabs.org/classify.html.
Paráda, všakže?
A tie unicode?
Ak predsa len niekto túži po zadávaní unicode znakov a emotikonov, samozrejme že sa to dá. Je na to potrebný balík hwemoji (príkaz \usepackage{hwemoji} v preambule). A existujú aj iné rozšírenia.
Ak sa pozrieme tomuto hwemoji pod sukňu zbadáme, že on prekladá zadané unicode znaky na príslušný vektorový obrázok (všetky uložené ako osobitná stránka v malom PDF) a toto ďalšími príkazmi renderuje ako vektorový obrázok.
Takže fungujuje to tak, že normálne zadáme unicode znak (napr. ✅, ❌, 📅, ⏳, 🔔, ✂️, 📁 …) a o viac sa nestaráme. Výstup môže vyzerať takto:
 |
| Obr. 3: Vyexportované unicode znaky. |
Ako zadávať unicode znaky - to závisí od editora. V Emacse je to ľahké vďaka kdejakým rozšíreniam i vstavaným funkciám. Ja som si na to spravil vlastné menu s kategóriami, samozrejme ide aj pomocu fuzzy vyhľadávania pomocou názvu alebo čísla.
Vyhodnocovanie kódu priamo v dokumente
No iste, prečo by toto niekto vlastne chcel?
Jednou z dobrých vlastností je písanie inicializačných skriptov pre Emacs, kde sa využíva štruktúrovanosť org dokumentu.
Ale má to i iné výhody - napríklad pri písaní tutoriálov, kníh, dokumentácie - ujal sa pre to pojem literate programming. A tiež je možné mať v jednom súbore funkčné kódy viacerých jazykov súčasne! Ďalej je tu určitá interaktívnosť a možnosť okamžite vidieť výsledky.
Org umožňuje exportovať hotové dokumenty do rôznych formátov, pričom zachováva vo svojej štruktúre kód i jeho výsledky. Tiež možno integrovať analýzu a spracovanie dát priamo v rámci dokumentov, čo uľahčuje prácu s rôznymi zdrojmi a údajmi - typicky ten gnuplot v minulej časti.
Podmienkou je mať, okrem nainštalovaj podpory (rozšírenia) Babel v preambule org súboru: #+PROPERTY: header-args :eval t
A zadanie bloku kódu je nasledovné:
#+begin_src sh :results verbatim :exports both echo "Kernel = $(uname -r)" echo "Hostname = $(hostname)" echo "Username = $(whoami)" echo "Dátum = $(date)" echo "Aktuálny adresár = $(pwd)" echo "Export v čase = $(date +"%T")" #+end_src
alebo
#+begin_src C :includes <stdio.h> :results verbatim :exports both
int a = 1;
int b = 2;
printf("%d + %d = %d\n", a, b, (a + b));
#+end_src
V príkladoch vidíme, že je možnosť zvolenia, ako sa výsledok bude exportovať. Sú možnosti ako do iného súboru, tabuľky, ako verbatim text,… Taktiež je možné „nainkludovať“ potrebné knižnice.
A automaticky vložený výsledok do pdf súboru môže vyzerať napríklad takto:
 |
| Obr. 4: Automaticky vložený vyhodnotený kód. |
Záver
Verím, že je to zaujímavé čítanie - odlišné od opisu nejakého textového procesora. A nabudúce si ukážeme, ako spájať LaTeX-ové dokumenty v org a tiež si niečo nakreslíme.
Pre pridávanie komentárov sa musíte prihlásiť.

Ešte pridám, že zoznam symbolov LaTeX-u je napríklad tu:
The Comprehensive LaTeX Symbol List
a je to úctyhodný 481-stranový dokument!